
аминопоиск
Синтаксис
aminolookup
aminolookup(SeqAA)
aminolookup('Code', CodeValue)
aminolookup('Integer', IntegerValue)
aminolookup('Abbreviation', AbbreviationValue)
aminolookup('Name', NameValue)
Описание
aminolookup отображает таблицу кодов аминокислоты, целых чисел, сокращений, имен и кодонов.
Поиск аминокислоты
| Код | Целое число | Сокращение | Имя аминокислоты | Кодоны |
|---|---|---|---|---|
A | 1 | Ala | Аланин | GCU GCC GCA GCG |
R | 2 | Arg | Аргинин | CGU CGC CGA CGG AGA AGG |
N | 3 | Asn | Аспарагин | AAU AAC |
D | 4 | Asp | Кислота аспарагиновой кислоты (Аспартат) | GAU GAC |
C | 5 | Cys | Цистеин | UGU UGC |
Q | 6 | Gln | Glutamine | CAA CAG |
E | 7 | Glu | Глутаминовая кислота (Глутамат) | GAA GAG |
G | 8 | Gly | Глицин | GGU GGC GGA GGG |
H | 9 | His | Гистидин | CAU CAC |
I | 10 | Ile | Изолейцин | AUU AUC AUA |
L | 11 | Leu | Лейцин | UUA UUG CUU CUC CUA CUG |
K | 12 | Lys | Лизин | AAA AAG |
M | 13 | Met | Метионин | AUG |
F | 14 | Phe | Фенилаланин | UUU UUC |
P | 15 | Pro | Пролин | CCU CCC CCA CCG |
S | 16 | Ser | Серин | UCU UCC UCA UCG AGU AGC |
T | 17 | Thr | Треонин | ACU ACC ACA ACG |
W | 18 | Trp | Триптофан | UGG |
Y | 19 | Tyr | Тирозин | UAU UAC |
V | 20 | Val | Valine | GUU GUC GUA GUG |
B | | Asx | Аспарагин или кислота Аспарагиновой кислоты (Аспартат) | AAU AAC GAU GAC |
Z | 22 | Glx | Glutamine или Glutamic acid (Глутамат) | CAA CAG GAA GAG |
X | 23 | Xaa | Любая аминокислота | Все кодоны |
* | 24 | END | Кодон завершения (остановка перевода) | UAA UAG UGA |
- | 25 | GAP | Разрыв неизвестной длины | NA |
aminolookup( преобразует между однобуквенными кодами и трехбуквенными сокращениями от последовательности аминокислот.SeqAA)
Если вы вводите один из неоднозначных однобуквенных кодов BZ, или X, эта функция отображает соответствующее сокращение от неоднозначного символа аминокислоты.
aminolookup('abc')
ans =
AlaAsxCysaminolookup('Code', отображает соответствующую аминокислоту трехбуквенное сокращение и имя.CodeValue)
aminolookup('Integer', отображает соответствующую аминокислоту однобуквенный код, трехбуквенное сокращение и имя.IntegerValue)
aminolookup('Abbreviation', отображает соответствующую аминокислоту однобуквенный код и имя.AbbreviationValue)
aminolookup('Name', отображает соответствующую аминокислоту однобуквенный код и трехбуквенное сокращение.NameValue)
Начиная с биоинформатики — превращение последовательностей ДНК в белковые последовательности
Дата публикации Aug 13, 2017
В этой статье мы узнаем о белках и о том, как преобразовать последовательность ДНК в последовательность белка. Я предлагаю вам прочитать мою предыдущую статью оНуклеотиды и нити ДНКЕсли вы пропустили это, то эта статья будет иметь больше смысла, как вы читаете. Итак, давайте перейдем к белкам.
Белкибольшие цепочечные молекулы, которые сделаны изаминокислоты, Белки отличаются друг от друга главным образом по последовательности аминокислот, которая определяется нуклеотидной последовательностью их генов. Прежде чем перейти к белкам, давайте посмотрим, что такое аминокислоты.
Структура аминокислоты(https://en.wikipedia.org/wiki/Amino_acid)Аминокислотысложные органические молекулы, в основном изуглерод,водород,кислород, а такжеазотнаряду с несколькими другими атомами. Содержитаминогруппаикарбоксильная группавместе сбоковая цепь(Группа R), которая специфична для каждой аминокислоты.
Содержитаминогруппаикарбоксильная группавместе сбоковая цепь(Группа R), которая специфична для каждой аминокислоты.
В настоящее время известно около 500 аминокислот, но только 20 из них присутствуют в нашем генетическом коде. Эти 20 аминокислот являются строительными блоками, в которых мы заинтересованы.
20 общих аминокислот
На приведенной ниже диаграмме показаны 20 распространенных аминокислот, которые присутствуют в нашем генетическом коде, а также их полные имена, трехбуквенные коды и однобуквенные коды.
20 общих аминокислот(Сложный процент:http://www.compoundchem.com/2014/09/16/aminoacids/)Биохимики признали, что данный тип белка всегда содержит точно одинаковое количество общих аминокислот (обычно называетсяостатки) в той же пропорции. Например,
insulin = (30 glycines + 44 alanines + 5 tyrosines + 14 glutamines + .. .)
 . .)
. .)Кроме того, аминокислоты связаны вместе как цепь. Идентичность белка определяется его составом, а также точным порядком составляющих его аминокислот. Следовательно, инсулин может быть представлен как
insulin = MALWMRLLPLLALLALWGPDPAAAFVNQHLCGSHLVEALYLVCGERG FFYTPKTRREAEDLQVGQVELGGGPGAGSLQPLALEGSLQKRGIVEQCCTSICSLYQLENYCN
Белки образуются из аминокислот с ихамина такжекарбоксилгруппы, чтобы сформировать связи, известные какпептидные связимежду последовательными остатками в последовательности. Две диаграммы, приведенные ниже, показывают, как свободные аминокислоты образуют белок путем образования пептидных связей.
Свободные аминокислоты(Wiley: Биоинформатика для чайников, 2-е издание) Аминокислоты, соединенные вместе для образования молекулы белка(Wiley: Биоинформатика для чайников, 2-е издание)Вы можете видеть, что есть неиспользованная аминогруппа слева и неиспользованная карбоксильная группа справа. Эти конечности соответственно называютсяN-конеца такжеС-конецбелковой цепи. Последовательность белка читается по составляющим его аминокислотам, перечисленным в порядке от N-конца до C-конца. Следовательно, последовательность белка, найденная на приведенной выше диаграмме, будет
Эти конечности соответственно называютсяN-конеца такжеС-конецбелковой цепи. Последовательность белка читается по составляющим его аминокислотам, перечисленным в порядке от N-конца до C-конца. Следовательно, последовательность белка, найденная на приведенной выше диаграмме, будет
MAVLD = Met-Ala-Val-Leu-Asp
= Methionine–Alanine-Valine–Leucine-Aspartic
Когда вы знаете последовательность ДНК, вы можете перевести ее в соответствующую последовательность белка, используягенетический код, Это так же, как сама клетка генерирует последовательность белка. Этот процесс известен какПеревод ДНК в белок,
генетический код(упоминается какДНК кодон столдля последовательностей ДНК)показывает, как мы однозначно связываем 4-нуклеотидную последовательность (A, T, G, C) с набором из 20 аминокислот. Он описывает набор правил, по которым информация, закодированная в генетическом материале, транслируется живыми клетками в белки. Диаграмма, приведенная ниже, показывает таблицу кодонов ДНК в виде диаграммы.
Диаграмма, приведенная ниже, показывает таблицу кодонов ДНК в виде диаграммы.
Как использовать генетическую кодовую диаграмму для перевода ДНК в белок
Сначала вы должны получить строку ДНК.
ATGGAAGTATTTAAAGCGCCACCTATTGGGATATAAG
Затем начните читать последовательности из 3 нуклеотидов (один триплет) за раз.
ATG GAA GTA TTT AAA GCG CCA CCT ATT GGG ATA TAA G...
Теперь используйте генетическую кодовую таблицу, чтобы прочитать, какая аминокислота соответствует текущему триплету (технически называемаякодоны). Первый круг, начинающийся с центра, представляет первый символ триплета, второй круг представляет второй символ, а третий круг представляет последний символ. После трансляции вы получите последовательность белка, которая соответствует вышеупомянутой последовательности ДНК.
M E V F K A P P I G I STOP
M E V F K A P P I G I
ТАА,ТЕГа такжеTGAизвестны каксигналы завершениягде вы останавливаете процесс перевода.
Код Python, приведенный ниже, берет последовательность ДНК и преобразует ее в соответствующую последовательность белка. Я создал словарь для хранения информации генетической кодовой диаграммы. Не стесняйтесь опробовать код и посмотреть, что получится.
Я дал ту же последовательность ДНК, которую мы обсуждали ранее, в качестве входных данных вsample_dna.txtфайл.
ATGGAAGTATTTAAAGCGCCACCTATTGGGATATAAG
Ниже приведены результаты, полученные
Перевод ДНК в вывод белкаЕсли вы знаете, где начинается кодирующая белок область в последовательности ДНК, ваш компьютер может с помощью простого кода сгенерировать соответствующую последовательность белка, состоящую из аминокислот. Многие программы анализа последовательностей используют этот метод трансляции, поэтому вы можете обрабатывать последовательности ДНК как виртуальные белковые последовательности с помощью вашего компьютера.
Надеюсь, вам понравилось читать эту статью и вы узнали что-то полезное.
Поскольку я все еще новичок в этой области, я хотел бы услышать ваш совет. 😇
Следите за моей следующей статьей о биоинформатике, которая будет о последовательностях РНК.
Спасибо за чтение … 😃
Оригинальная статья
Аминокислоты
АминокислотыВернуться на [главную страницу]. Вернуться на [предыдущую страницу].
Аминокислоты.
Аминокислоты Трехбуквенный Однобуквенный Молекулярный (английский) код код вес Alanine Ala A 89 Arginine Arg R 174 Asparagine Asn N 132 Aspartic acid Asp D 133 Asparagine or Aspartic acid Asx B -/- Cysteine Cys C 121 Glutamine Gln Q 146 Glutamic acid Glu E 147 Glutamine or Glutamic acid Glx Z -/- Glycine Gly G 75 Histidine His H 155 Isoleucine Ile I 131 Leucine Leu L 131 Lysine Lys K 146 Methionine Met M 149 Phenylalanine Phe F 165 Proline Pro P 115 Serine Ser S 105 Threonine Thr T 119 Tryptophan Trp W 204 Tyrosine Tyr Y 181 Valine Val V 117
Аминокислоты
(химические формулы)
наименование (английский, русский)
Alanine, Аланин
H
¦
CH3-C-COO(-)
¦
NH3
(+)
Valine, Валин
CH3 H
\ ¦
CH-C-COO(-)
/ ¦
CH3 NH3
(+)
Leucine, Лейцин
CH3 H
\ ¦
CH-CH2-C-COO(-)
/ ¦
CH3 NH3
(+)
Isoleucine, Изолейцин
H
¦
CH3-CH2-CH--C-COO(-)
¦ ¦
CH 3 NH3
(+)
Proline, Пролин
H2
/C
H2C \
¦ C-COO(-)
H2C / \
\N H
H
Phenylalanine, Фенилаланин
H
¦
C6H5-CH2-C-COO(-)
¦
NH3
(+)
Tryptophan, Триптофан
H
¦
//\ ---C--CH2-C-COO(-)
¦ ¦ ¦ ¦
\\/ \ /CH NH3
N (+)
H
Methionine, Метионин
H
¦
CH3-S-CH2-CH2-C-COO(-)
¦
NH3
(+)
Glycine, Глицин
H ¦ H-C-COO(-) ¦ NH3 (+)
Serine, Серин
H
¦
HO-CH2-C-COO(-)
¦
NH3
(+)
Threonine, Треонин
H
¦
CH3-CH-C-COO(-)
¦ ¦
OH NH3
(+)
Cysteine, Цистеин
H
¦
HS-CH2-C-COO(-)
¦
NH3
(+)
Tyrosine, Тирозин
H
¦
HO-C6H4-CH2-C-COO(-)
¦
NH3
(+)
Asparagine, Аспарагин
NH2 H
¦ ¦
O=C-CH2-C-COO(-)
¦
NH 3
(+)
Glutamine, Глутамин
NH2 H
¦ ¦
O=C-CH2-CH2-C-COO(-)
¦
NH3
(+)
Кислые аминокислоты (несущие отрицательный заряд)
Aspartic acid, Аспарагиновая кислота
H
¦
(-)OOC-CH2-C-COO(-)
¦
NH3
(+)
Glutamic acid, Глутаминовая кислота
H
¦
(-)OOC-CH2-CH2-C-COO(-)
¦
NH3
(+)
Основные аминокислоты (несущие положительный заряд)
Lysine, Лизин
H
(+) ¦
H3N-CH 2-CH2-CH2-CH2-C-COO(-)
¦
NH3
(+)
Arginine, Аргинин
H
¦
H2N-C-NH-CH2-CH2-CH2-C-COO(-)
¦ ¦
NH2 NH3
(+) (+)
Histidine, Гистидин (при pH 6.
 0)
0)
H
¦
HC===C-CH2-C-COO(-)
¦ ¦ ¦
HN NH NH3
(+)\\ / (+)
C
H
Аминокислоты использование — Справочник химика 21
Аминокислота Использованный эфир дуемых соединений Литература [c.99]Создание новых методов переработки и хранения пищевых продуктов, получение пищевых добавок (например, полимеров, продуцируемых микроорганизмами аминокислот), использование белка, синтезируемого одноклеточными организмами, и ферментов при переработке пищевого сырья [c.14]
Переработка аммиачного азота на синтез аминокислот в основном происходит в корнях, в листья поступают уже готовые аминокислоты. Использование аммиака на синтез аминокислот характеризуется весьма высокой скоростью, и уже в первые минуты после внесения меченого аммиачного азота в корнях растений можно обнаружить включение значительных количеств изотопа N 5 в состав аминокислот.
 [c.241]
В пищевой промышленности это создание новых методов переработки и хранения пищевых продуктов, получение пищевых добавок (например, полимеров, продуцируемых микроорганизмами, аминокислот), использование белка, синтезируемого одноклеточными организмами, и ферментов при переработке пищевого сырья. Применение ферментов для усовершенствования средств диагностики, создание тестовых систем на основе ферментов, использование микроорганизмов и ферментов при производстве сложных лекарств (например, стероидных), синтез новых антибиотиков и их использование в терапии инфекционной патологии животных. [c.252]
[c.241]
В пищевой промышленности это создание новых методов переработки и хранения пищевых продуктов, получение пищевых добавок (например, полимеров, продуцируемых микроорганизмами, аминокислот), использование белка, синтезируемого одноклеточными организмами, и ферментов при переработке пищевого сырья. Применение ферментов для усовершенствования средств диагностики, создание тестовых систем на основе ферментов, использование микроорганизмов и ферментов при производстве сложных лекарств (например, стероидных), синтез новых антибиотиков и их использование в терапии инфекционной патологии животных. [c.252] Еще один свойственный многим белкам элемент структуры — /3-изгиб. Рис. 2.25 показывает, что эта структура дает полипептидной цепи возможность резко менять направление. По аналогии с параметрами Р и можно рассчитать и конформационные параметры /3-изгиба для каждой аминокислоты. Использование их совместно сР иРр позволяет повысить точность конформационного анализа. Примечательно, что примерно в 12 белках. недавно исследованных Чоу и Фасманом, около 80% всех остатков находились в составе а-спиралей. /3-слоев и /3-изгибов и лишь остальные 20% не могли быть отнесены ни к какому определенному типу. [c.281]
Примечательно, что примерно в 12 белках. недавно исследованных Чоу и Фасманом, около 80% всех остатков находились в составе а-спиралей. /3-слоев и /3-изгибов и лишь остальные 20% не могли быть отнесены ни к какому определенному типу. [c.281]
Установлено, что для человека незаменимы восемь аминокислот. Использование в пищу белка, не содержащего какой-либо из иих, приводит к нарушению обмена веществ и заболеванию. [c.35] Одной из основных причин применения дериватизации в ГХ является перевод нелетучих соединений в более летучие. Особое место здесь занимают методы получения летучих производных аминокислот, которые в натуральном виде не только нелетучи, но и термически нестойки и поэтому их прямой анализ методом ГХ невозможен. В то же время актуальность задач качественного и количественного определения аминоки слот в биологии, биохимии, медицине и микробиологии стимулирует развитие методов получения и анализа летучих производных аминокислот.
 Использование метиловых эфиров N-тpифтopaцeтил-пpoизвoдныx [c.193]
Использование метиловых эфиров N-тpифтopaцeтил-пpoизвoдныx [c.193]АЕОС КЗЭ/ МЭКХ-УФ Энантиомеры аминокислот Использование в качестве хиральных селекторов циклодекстринов [2] [c.369]
SAMB1 КЗЭ — УФ Энантиомеры аминокислот Использование для дериватизации хирального реагента [47] [c.371]
СЬЗ. S с h о е п h е i m е г R., R i 1, 1, е п Ь е г g D. и др.. Исследования протеинового метаболизма. (Включает общее рассмотрение применепия изотопов к изу-чепшо протеинового метаболизма. Нормальное относительное содержание изотонов азота в аминокислотах. Использование масс-спектрометра для определения изотопов азота в органических соединениях.), 1. Biol. hem., 127, 285-351 (1939). [c.634]
Анализ кислых и нейтральных аминокислоте использованием литийцитратных буферов. Разделение аспарагина и глутамина в присутствии других аминокислот всегда представляет собой [c.61]
Эванс и сотрудники [105, 106] выращивали фибробласты мыши (линия L-929) на среде определенного химического состава, не содержащей белка. В эту среду входили 25 аминокислот (в том числе 13 аминокислот, использованных Иглом), а также ряд других соединений (например, инозит, витамин А, 1-аминобензоат, дифосфопиридиннуклеотид, дезоксигуанозин) еще не установлено, необходимы ли все эти соединения для роста и сохранности этих клеток. Сходная среда была предложена Хили и сотрудниками [107]. [c.132]
В эту среду входили 25 аминокислот (в том числе 13 аминокислот, использованных Иглом), а также ряд других соединений (например, инозит, витамин А, 1-аминобензоат, дифосфопиридиннуклеотид, дезоксигуанозин) еще не установлено, необходимы ли все эти соединения для роста и сохранности этих клеток. Сходная среда была предложена Хили и сотрудниками [107]. [c.132]
Бензиловые эфиры аминокислот. Использование бензиловых эфиров в карбобензокси-методе синтеза пептидов имеет то преимущество, что обе защитные группы можно удалить одновременно каталитическим гидрированием. Однако при прямой этерификации с применением бензилового спирта и минеральной кислоты получаются низкие выходы. По методу Эрлангера и Бранда [15] (ошибочно приписываемому Максу Бергманну) аминокислоту превращают в N-карбоксиангидрид (2), который с бензиловым спиртом в присутствии хлористого водорода дает бензиловый эфир (3). В первоначальной методике N-карбоксиангидрид (оксазолидиндион-2,5) получали косвенным методом, однако последующие исследователи использовали реакцию аминокислоты с Ф. [16—18]. Обработка ангидрида (2) в сухом диоксане НС1 или НВг дает аналитически чистый галоген-гидрат ацилгалогенида [18]. [c.80]
[16—18]. Обработка ангидрида (2) в сухом диоксане НС1 или НВг дает аналитически чистый галоген-гидрат ацилгалогенида [18]. [c.80]
Она наглядно доказывает, что неорганически синтезированные пептиды построены иэ поразительно большого числа различных аминокислот. В качестве растворителя при хроматографии использовали водонасыщенный фенол 1 — гидролизат полимера, полученного с использованием эквивалентных количеств аминокислот 2 — гидролизат полимера, полученного с использованием избытка глутаминовой кислоты. Пятна с надписями — аминокислоты, использованные в качестве стандарта. [c.112]
Аллоспецифичные структурные мотивы в молекулах пептидов, элюированных из комплексов с молекулами МНС класса I гаплотипа Н-2КЬ или Н-2К . Молекулы МНС вьщеляли методом иммунопреципитации. Связанные с ними пептиды были очищены и секвенированы. Якорные аминокислотные остатки, наиболее часто встречающиеся в определенных позициях, определены как доминантные, а встречающиеся лишь относительно часто — как функциональные. В позициях без указания определенной аминокислоты с равной вероятностью встречается несколько различных остатков. Для обозначения аминокислот использован однобуквенный код. Вверху изображены пептидсвя-зывающие полости (вид сверху) двух молекул МНС класса I разных гаплотипов. Позиции якорных остатков в составе пептида, связанного с молекулой МНС каждого гаплотипа, выделены цветом. [c.162]
В позициях без указания определенной аминокислоты с равной вероятностью встречается несколько различных остатков. Для обозначения аминокислот использован однобуквенный код. Вверху изображены пептидсвя-зывающие полости (вид сверху) двух молекул МНС класса I разных гаплотипов. Позиции якорных остатков в составе пептида, связанного с молекулой МНС каждого гаплотипа, выделены цветом. [c.162]
введение для айтишников / Хабр
Приятно видеть, что хабравчане регулярно интересуется другими предметными областями – например, биологией (более конкретно – структурой и функцией биологических макромолекул). Однако некоторые посты (например,
этот), вызывают у специалиста просто физическую боль из-за обилия совершенно диких фактологических ошибок. В этом посте мне хочется рассказать о структуре и функции белка. О том, что мы знаем и о том, чего не знаем, а так же об имеющихся в этой области вычислительных задачах, требующих решения и интересных IT-специалистам. Постараюсь рассказывать сжато и тезисно, чтобы информации было больше, а воды – меньше.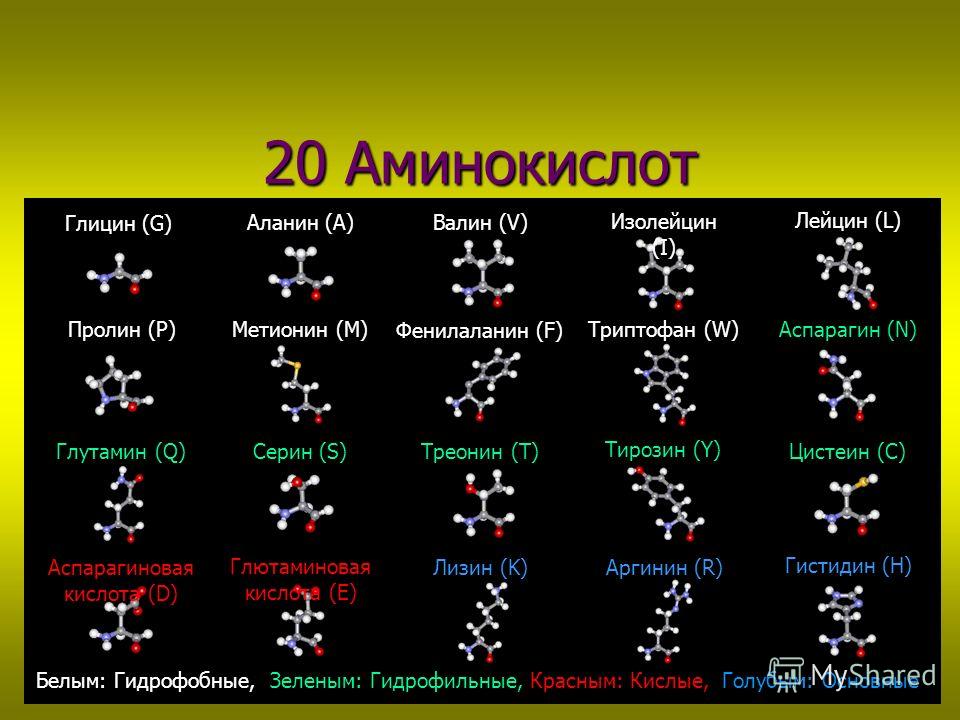 Всех, интересующихся структурой белков, прошу под кат, там очень много букв.
Всех, интересующихся структурой белков, прошу под кат, там очень много букв.
1. Почему белки важны?
Как сказал Фридрих Энгельс, “Жизнь есть способ существования белковых тел”. В 19 веке еще не знали о роли ДНК в наследовании генетической информации, но утверждение дяди Фридриха в значительной мере справедливо до сих пор – основную работу в наших клетках совершают именно белки. Это и поддержание структуры (формы клеток), и химический катализ, и моторная функция (сокращение мышц, например), и транспорт (скажем, белок гемоглобин переносит кислород из легких в ткани и углекислый газ в обратном направлении) и сложные регуляторные функции по поддержанию постоянства внутренней среды (скажем, белковые гормоны и всякие внутриклеточные регуляторные системы) и многие другие. Словом, если в нашем организме что-то происходит, в это обязательно вовлечены белки (хотя и не только они).
2. Что такое белок?
С химической точки зрения белок – это линейный (неветвящийся) полимер, состоящий из монотонно повторяющихся одинаковых блоков «основной цепи», к которым приделаны различные «боковые группы». Так как блоки основной цепи несимметричны, вся полипептидная цепь белка имеет направление, различают N- и C-конец полипептидной цепи.
Так как блоки основной цепи несимметричны, вся полипептидная цепь белка имеет направление, различают N- и C-конец полипептидной цепи.
Длина цепи – от 70 до более чем 1000 мономеров (аминокислотных остатков), средняя длина для высших организмов – примерно 500-600 аминокислотных остатков, для бактерий эта величина будет меньше, скорее 300-400 остатков. Всего в природе существует 20 стандартных аминокислот, одинаковых и для бактерии и для человека, то есть из основной цепи могут торчать 20 разных боковых групп.
(Тут возможна поправка – некоторые химические группы могут быть модифицированны после синтеза белка, например, фосфорилированы. Однако это не рассматривается как другая аминокислота, а рассматривается как продукт модификации исходной. Так же у высших организмов возможно встраивание двух неканонических аминокислот, но это редкое событие. То есть, строго говоря, разных аминокислот 22, из них 20 основных и 2 редкие, плюс некоторые боковые группы могут быть изредка химически модифицированы).
Из поколения в поколение генетическая информация передается в виде ДНК, в ней есть так называемые «белок-кодирующие области». В этих местах ДНК однозначным образом (для ботанов – с точностью до альтернативного сплайсинга и редактирования РНК) закодирована информация о линейной последовательности аминокислот для синтеза данного белка, плюс в клетке есть соответствующие машины, способные синтезировать белок по информации, изначально закодированной в ДНК.
Так как белок – линейный полимер, собранный из 20 стандартных мономеров, его так называемую «первичную структуру» легко представить в виде строки, например так:
>small ubiquitin-related modifier 3 precursor [Homo sapiens] MSEEKPKEGVKTENDHINLKVAGQDGSVVQFKIKRHTPLSKLMKAYCERQG LSMRQIRFRFDGQPINETDTPAQLEMEDEDTIDVFQQQTGGVPESSLAGHSF
Это аминокислотная последовательность маленького человеческого белка в формате FASTA, первая строчка, начинающаяся с «>», описывает его название, после чего следует последовательность аминокислот в соответствии со стандартной кодировкой (например, М –метиони, S – серин и тд, всего 20 букв стандартного однобуквенного кода), слева – N-конец белка, справа – его С-конец. Для разных белков длина строки будет очевидно разной, так как белки имеют разную длину. Последовательности всех известных белков можно найти в открытом доступе здесь: www.ncbi.nlm.nih.gov
Для разных белков длина строки будет очевидно разной, так как белки имеют разную длину. Последовательности всех известных белков можно найти в открытом доступе здесь: www.ncbi.nlm.nih.gov
3. Структура белка
Хорошо, с первичной структурой разобрались, но разве белок работает в развернутом линейном виде? Конечно нет. Тут надо заметить, что со структурной точки зрения есть разные классы белков: глобулярные, мембранные и фибриллярные. Мембранные белки, как следует из названия, живут только в клеточных мембранах, для стабилизации их структуры нужно особое окружение мембраны, мы не будем их рассматривать в этом обзоре. Фибриллярные белки имеют простое регулярное строение, похожи на вытянутые волокна, они не растворимы в воде и выполняют структурные функции (например, из кератина состоят волосы, к фибриллярным белкам относится белок из натурального шёлка). Недавно стали выделять класс разупорядоченных белков – белков, не обладающих постоянной трехмерной структурой, либо приобретающих ее только на короткое время при взаимодействии с другими белками.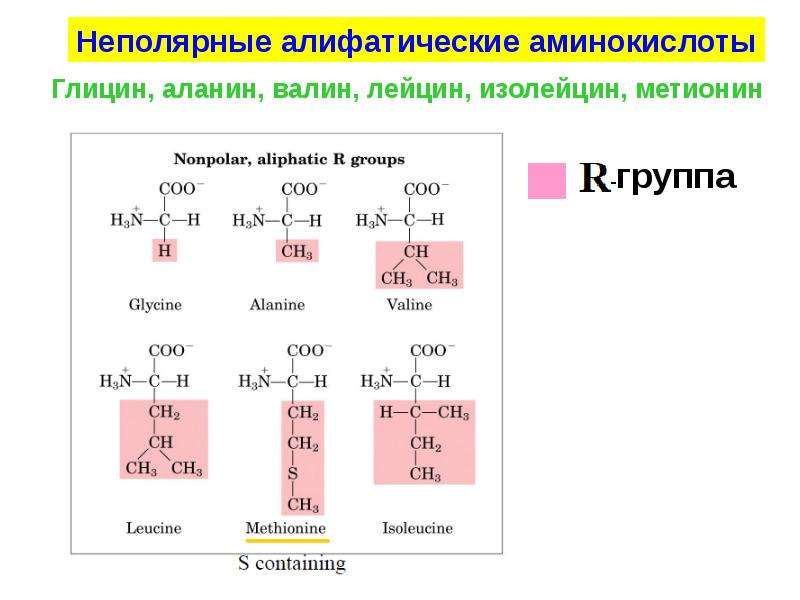 Наиболее интересный с практической точки зрения класс белков, который мы и будем рассматривать – глобулярные водорастворимые белки, к этому классу относится большинство белков.
Наиболее интересный с практической точки зрения класс белков, который мы и будем рассматривать – глобулярные водорастворимые белки, к этому классу относится большинство белков.
Линейная полипептидная цепь в воде способна самопроизвольно сворачиваться в сложную трехмерную структуру (глобулу) и только в таком свернутом виде белки могут выполнять химический катализ и прочую интересную работу. Поэтому нам принципиально важно знать именно трехмерную укладку белка, так как только на этом уровне становится понятно, как белок работает.
Вопрос: сколько трехмерных структур соответствует конкретному белку?
Ответ: Одна, с точностью до небольшой подвижности маленьких «разупорядоченных» петель. Известно ровно одно исключение, когда одной последовательности соответствуют 2 достаточно разные структуры, это прионы.
Вопрос: Почему у белка только одна трехмерная структура?
Ответ: для химического катализа нам нужно расположить соответствующие химические группы строго определенным образом в пространстве. Для этого нужна жесткая структура. То есть весь белок должен быть жестким, чтобы поддерживать химические группы аминокислот активного центра в нужных местах (в реальности многие белки состоят из двух и более жестких частей, которые могут двигаться друг относительно друга, это нужно для регуляции активности белка (аллостерическая регуляция), чтобы некий сигнал мог включать и выключать химическую активность белка-фермента). Чтобы структура была жесткой и стабильной, природа позаботилась о том, чтобы структура каждого белка соответствовала энергетическому минимуму данной системы атомов и этот минимум был настолько глубоким, чтобы белок из него не «выпрыгнул». Все другие, паразитные структуры, обладают большей энергией и белок все равно сваливается в энергетический минимум, соответствующий нативной структуре.
Для этого нужна жесткая структура. То есть весь белок должен быть жестким, чтобы поддерживать химические группы аминокислот активного центра в нужных местах (в реальности многие белки состоят из двух и более жестких частей, которые могут двигаться друг относительно друга, это нужно для регуляции активности белка (аллостерическая регуляция), чтобы некий сигнал мог включать и выключать химическую активность белка-фермента). Чтобы структура была жесткой и стабильной, природа позаботилась о том, чтобы структура каждого белка соответствовала энергетическому минимуму данной системы атомов и этот минимум был настолько глубоким, чтобы белок из него не «выпрыгнул». Все другие, паразитные структуры, обладают большей энергией и белок все равно сваливается в энергетический минимум, соответствующий нативной структуре.
Вопрос: на чем держится трехмерная структура белка?
Ответ: если коротко, то в основном на большом количестве нековалентных взаимодействий. В принципе, химические группы белка могут образовывать: (1) водородную связь, эти группы есть и в основной цепи и у некоторых боковых групп, (2) ионную связь – электростатическое взаимодействие между разноименно заряженными боковыми группами, (3) Ван-дер-Ваальсово взаимодействие и (4) гидрофобный эффект, на котором держится общая структура белка.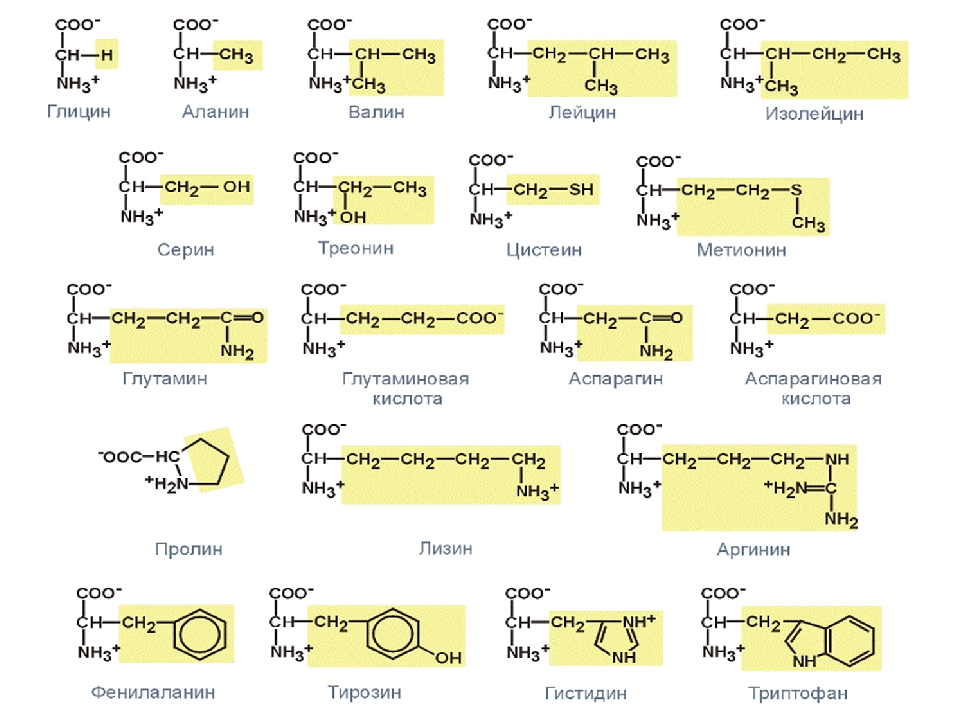 Суть в том, что в белке всегда есть гидрофобные ароматические остатки, им энергетически невыгодно контактировать с полярными молекулами воды, а выгодно «слипнуться» друг с другом. Таким образом, при сворачивании белка гидрофобные группы выталкиваются из водного окружения, «слипаясь» друг с другом и формируя «гидрофобное ядро», а полярные и заряженные группы, наоборот, стремятся в водное окружение, формируя поверхность белковой глобулы. Так же (5) боковые группы двух остатков цистеина могут образовать между собой дисульфидный мостик – полноценную ковалентную связь, жестко фиксирующую белок.
Суть в том, что в белке всегда есть гидрофобные ароматические остатки, им энергетически невыгодно контактировать с полярными молекулами воды, а выгодно «слипнуться» друг с другом. Таким образом, при сворачивании белка гидрофобные группы выталкиваются из водного окружения, «слипаясь» друг с другом и формируя «гидрофобное ядро», а полярные и заряженные группы, наоборот, стремятся в водное окружение, формируя поверхность белковой глобулы. Так же (5) боковые группы двух остатков цистеина могут образовать между собой дисульфидный мостик – полноценную ковалентную связь, жестко фиксирующую белок.
Соответственно, все аминокислоты делятся на гидрофобные, полярные (гидрофильные), положительно и отрицательно заряженные. Плюс цистеины, способные образовывать ковалентную связь между собой. Особыми свойствами обладают глицин – у него отсутствует боковая группа, сильно ограничивающая конформационную подвижность других остатков, поэтому он может очень сильно «гнуться» и находится в местах, где белковую цепь надо развернуть. У пролина же, наоборот, боковая группа образует кольцо, ковалентно связанное с основной цепью, жестко фиксируя ее конформацию. Пролины встречаются там, где надо сделать белковую цепь жесткой и негнущейся. Многие заболевания связаны с мутацией пролина на глицин, из-за чего структура белка слегка «плывет».
У пролина же, наоборот, боковая группа образует кольцо, ковалентно связанное с основной цепью, жестко фиксируя ее конформацию. Пролины встречаются там, где надо сделать белковую цепь жесткой и негнущейся. Многие заболевания связаны с мутацией пролина на глицин, из-за чего структура белка слегка «плывет».
Вопрос: откуда вообще мы знаем о трехмерных структурах белка?
Ответ: из эксперимента, это абсолютно надежные данные.
Сейчас есть 3 метода для экспериментального определения структуры белка: ядерно-магнитный резонанс (ЯМР), cryo-EM (электронная микроскопия) и рентгеноструктурный анализ кристаллов белка.
ЯМР позволяет определить структуру белка в растворе, но он работает только для очень маленьких белков (для больших невозможно сделать деконволюцию).
Этот метод был важен для общего доказательства того, что у белка только одна трехмерная структура и что структура белка в кристалле идентична структуре в растворе. Это очень дорогой метод, так как требуется получить белок с изотопными метками.
Cryo-EM заключается в простой заморозке раствора белка и микроскопии. Минус метода – низкое разрешение (видна лишь общая форма молекулы, но не видно, как она устроена внутри), плюс плотность белка близка к плотности воды/растворителя, поэтому сигнал тонет в высоком уровне шума. В этом методе активно применяются компьютерные технологии работы с картинками и статистика для вытягивания сигнала из шума.
Отбираются миллионы картинок молекул белка, проводится разделение на классы в зависимости от ориентации молекулы относительно подложки, усреднение по классам, генерация eigenimages, новый раунд усреднения и так пока не сойдется. Потом из информации из разных классов можно восстановить трехмерный вид молекулы с низким разрешением. Если же есть внутренняя симметрия частиц (например, при cryo-EM анализе вирусов), то можно еще каждую частицу поусреднять в соответствии с операторами симметрии – тогда разрешение будет еще лучше, но хуже, чем в случае рентгеноструктурного анализа.
Рентгеноструктурный анализ – основной способ определения структур белка. Главный плюс – потенциально можно получить кристаллы даже очень больших комплексов из многих десятков белков (например, именно так была определена структура рибосомы – Нобелевская премия 2009 года). Минус метода – вначале нужно получить кристалл белка, но далеко не каждый белок хочет кристаллизоваться.
Зато после того, как кристалл получен, по дифракции рентгеновского излучения можно однозначно определить положения всех (упорядоченных) атомов в молекуле белка, этот метод дает самое высокое разрешение и позволяет в лучших случаях видеть позиции отдельных атомов. Было доказано, что структура белка в кристалле однозначно соответствует структуре в растворе.
Сейчас действует конвенция – если ты определил структуру белка любым из экспериментальных физических методов, структура должна быть помещена в открытый доступ в банк данных белковых структур (Protein Data Bank – PDB, www.pdb.org ), в настоящее время там находится более 90 000 структур (впрочем, многие из них повторяющиеся, например, комплексы одного и того же белка с разными малыми молекулами, такими, как лекарственные средства). В PDB все структуры лежат в стандартном формате, называющемся, внезапно, pdb. Это текстовый формат, в котором каждому атому структуры соответствует одна строчка, в которой указан номер атома в структуре, название атома (углерод, азот и тд), название аминокислоты, в которую входит атом, название цепи белка (A, B, C и тд, если это кристалл комплекса из нескольких белков), номер аминокислоты в цепи и трехмерные координаты атома в ангстремах относительно ориджина, плюс так называемые температурный фактор и заселённость (это сугубо кристаллографические параметры).
В PDB все структуры лежат в стандартном формате, называющемся, внезапно, pdb. Это текстовый формат, в котором каждому атому структуры соответствует одна строчка, в которой указан номер атома в структуре, название атома (углерод, азот и тд), название аминокислоты, в которую входит атом, название цепи белка (A, B, C и тд, если это кристалл комплекса из нескольких белков), номер аминокислоты в цепи и трехмерные координаты атома в ангстремах относительно ориджина, плюс так называемые температурный фактор и заселённость (это сугубо кристаллографические параметры).
ATOM 1 N HIS A 17 -12.690 8.753 5.446 1.00 29.32 N ATOM 2 CA HIS A 17 -11.570 8.953 6.350 1.00 21.61 C ATOM 3 C HIS A 17 -10.274 8.970 5.544 1.00 22.01 C ATOM 4 O HIS A 17 -10.193 8.315 4.491 1.00 29.95 O ATOM 5 CB HIS A 17 -11.462 7.820 7.380 1.00 23.64 C ATOM 6 CG HIS A 17 -12.
 551 7.811 8.421 1.00 21.18 C
ATOM 7 ND1 HIS A 17 -13.731 7.137 8.194 1.00 28.94 N
ATOM 8 CD2 HIS A 17 -12.634 8.384 9.644 1.00 21.69 C
ATOM 9 CE1 HIS A 17 -14.492 7.301 9.267 1.00 27.01 C
ATOM 10 NE2 HIS A 17 -13.869 8.058 10.168 1.00 22.66 N
ATOM 11 N ILE A 18 -9.269 9.660 6.089 1.00 19.45 N
ATOM 12 CA ILE A 18 -7.910 9.377 5.605 1.00 18.67 C
ATOM 13 C ILE A 18 -7.122 8.759 6.749 1.00 16.24 C
ATOM 14 O ILE A 18 -7.425 8.919 7.929 1.00 18.80 O
ATOM 15 CB ILE A 18 -7.228 10.640 5.088 1.00 20.22 C
ATOM 16 CG1 ILE A 18 -7.062 11.686 6.183 1.00 18.52 C
ATOM 17 CG2 ILE A 18 -7.981 11.176 3.889 1.00 24.61 C
ATOM 18 CD1 ILE A 18 -6.161 12.824 5.749 1.00 28.
551 7.811 8.421 1.00 21.18 C
ATOM 7 ND1 HIS A 17 -13.731 7.137 8.194 1.00 28.94 N
ATOM 8 CD2 HIS A 17 -12.634 8.384 9.644 1.00 21.69 C
ATOM 9 CE1 HIS A 17 -14.492 7.301 9.267 1.00 27.01 C
ATOM 10 NE2 HIS A 17 -13.869 8.058 10.168 1.00 22.66 N
ATOM 11 N ILE A 18 -9.269 9.660 6.089 1.00 19.45 N
ATOM 12 CA ILE A 18 -7.910 9.377 5.605 1.00 18.67 C
ATOM 13 C ILE A 18 -7.122 8.759 6.749 1.00 16.24 C
ATOM 14 O ILE A 18 -7.425 8.919 7.929 1.00 18.80 O
ATOM 15 CB ILE A 18 -7.228 10.640 5.088 1.00 20.22 C
ATOM 16 CG1 ILE A 18 -7.062 11.686 6.183 1.00 18.52 C
ATOM 17 CG2 ILE A 18 -7.981 11.176 3.889 1.00 24.61 C
ATOM 18 CD1 ILE A 18 -6.161 12.824 5.749 1.00 28. 21 C
ATOM 19 N ASN A 19 -6.121 8.023 6.349 1.00 15.46 N
ATOM 20 CA ASN A 19 -5.239 7.306 7.243 1.00 14.34 C
ATOM 21 C ASN A 19 -4.012 8.178 7.507 1.00 14.83 C
ATOM 22 O ASN A 19 -3.431 8.715 6.575 1.00 18.03 O
ATOM 23 CB ASN A 19 -4.825 6.003 6.573 1.00 17.71 C
ATOM 24 CG ASN A 19 -6.062 5.099 6.413 1.00 21.26 C
ATOM 25 OD1 ASN A 19 -6.606 4.651 7.400 1.00 26.18 O
ATOM 26 ND2 ASN A 19 -6.320 4.899 5.151 1.00 31.73 N
21 C
ATOM 19 N ASN A 19 -6.121 8.023 6.349 1.00 15.46 N
ATOM 20 CA ASN A 19 -5.239 7.306 7.243 1.00 14.34 C
ATOM 21 C ASN A 19 -4.012 8.178 7.507 1.00 14.83 C
ATOM 22 O ASN A 19 -3.431 8.715 6.575 1.00 18.03 O
ATOM 23 CB ASN A 19 -4.825 6.003 6.573 1.00 17.71 C
ATOM 24 CG ASN A 19 -6.062 5.099 6.413 1.00 21.26 C
ATOM 25 OD1 ASN A 19 -6.606 4.651 7.400 1.00 26.18 O
ATOM 26 ND2 ASN A 19 -6.320 4.899 5.151 1.00 31.73 N
Далее есть специальные программы, которые по данным из этого текстового файла могут графически отображать красивую трехмерную структуру молекулы белка, которую можно покрутить на экране монитора и, как говорил Гай Додсон, «дотронуться мышкой до молекулы» (например, PyMol, CCP4mg, старый RasMol). То есть смотреть на структуры белка просто – ставишь программу, загружаешь нужную структуру из PDB и наслаждаешься красотой природы.
4. Анализируем структуру
Итак, мы поняли основную идею: белок — линейный полимер, сворачивающийся в водном растворе под действием множества слабых взаимодействий в стабильную и единственную для данного белка трехмерную структуру, и способный в таком виде выполнять свою функцию. Различают несколько уровней организации белковых структур. Выше мы уже познакомились с первичной структурой – линейной последовательностью аминокислот, которую можно выписать в строчку.
Вторичная структура белка определяется взаимодействием атомов основной цепи белка. Как уже было сказано выше, в состав основной цепи белка входят доноры и акцепторы водородной связи, таким образом, основная цепь может приобретать некоторую структуру. Точнее, несколько разных структур (детали все-таки зависят от различающихся боковых групп), так как возможно образование разных альтернативных водородных связей между группами основной цепи. Структуры бывают такие: альфа-спираль, бета-листы (состоящие из нескольких бета-тяжей), которые бывают параллельными и анти-параллельными, бета-поворот. Плюс часть цепи может и не иметь выраженной структуры, например в районе поворота петли белка. Эти типы структур имеют свои устоявшиеся схематичные обозначения – альфа-спираль в виде спирали или цилиндра, бета-тяжи в виде широких стрелок. Вторичную структуру удается достаточно достоверно предсказывать по первичной (стандартом является JPred), альфа-спирали предсказываются наиболее точно, с бета-тяжами бывают накладки.
Плюс часть цепи может и не иметь выраженной структуры, например в районе поворота петли белка. Эти типы структур имеют свои устоявшиеся схематичные обозначения – альфа-спираль в виде спирали или цилиндра, бета-тяжи в виде широких стрелок. Вторичную структуру удается достаточно достоверно предсказывать по первичной (стандартом является JPred), альфа-спирали предсказываются наиболее точно, с бета-тяжами бывают накладки.
Третичная структура белка определяется взаимодействием боковых групп аминокислотных остатков, это и есть трехмерная структура белка. Можно представить себе, что вторичная структура сформирована и теперь эти спирали и бета-тяжи хотят уложиться все вместе в компактную трехмерную структуру, чтобы все гидрофобные боковые группы спокойно «слиплись» вместе в глубине белковой глобулы, сформировав гидрофобное ядро, а полярные и заряженные остатки торчали наружу в воду, формируя поверхность белка и стабилизируя контакты между элементами вторичной структуры. Третичную структуру изображают схематически несколькими способами. Если просто отрисовать все атомы, то получится каша (хотя когда мы анализируем активный центр белка, то мы хотим смотреть как раз на все атомы активных остатков).
Если просто отрисовать все атомы, то получится каша (хотя когда мы анализируем активный центр белка, то мы хотим смотреть как раз на все атомы активных остатков).
Если мы хотим посмотреть, как устроен весь белок в общем, можно отобразить только некоторые атомы основной цепи, чтобы увидеть ее ход. Как вариант, можно нарисовать красивую схему, где поверх реального расположения атомов схематично нарисованы элементы вторичной структуры – так с первого взгляда видна укладка белка. После изучения всей структуры в общем, схематичном виде, можно отобразить химические группы активного центра и уже сосредоточиться на них. Задача предсказания третичной структуры белка – нетривиальная и в общем случае не решается, хотя может быть решена в частных случаях. Подробнее – ниже.
Четвертичная структура белка – да, есть и такая, правда не у всех белков. Многие белки работают сами по себе (мономеры, в данном случае под мономером имеется в виду одиночная свернутая полипептидная цепь, то есть белок целиком), тогда их четвертичная структура равна третичной. Однако достаточно много белков работает только в комплексе, состоящем из нескольких полипептидных цепей (субъединиц или мономеров — димеры, тримеры, тетрамеры, мультимеры), тогда вот такая сборка из нескольких отдельных цепей и называется четвертичной структурой. Самый банальный пример – состоящий из 4 субъединиц гемоглобин, самый красивый на мой взгляд пример – состоящий из 11 одинаковых субъединиц бактериальный белок TRAP.
Однако достаточно много белков работает только в комплексе, состоящем из нескольких полипептидных цепей (субъединиц или мономеров — димеры, тримеры, тетрамеры, мультимеры), тогда вот такая сборка из нескольких отдельных цепей и называется четвертичной структурой. Самый банальный пример – состоящий из 4 субъединиц гемоглобин, самый красивый на мой взгляд пример – состоящий из 11 одинаковых субъединиц бактериальный белок TRAP.
5. Вычислительные задачи
Белок – сложная система из тысяч атомов, поэтому без использования компьютеров в структуре белка не разобраться. Задач, как решенных на приемлемом уровне, так и совсем не решенных, множество. Перечислю наиболее актуальные:
На уровне первичной структуры – поиск белков с похожей аминокислотной последовательностью, построение по ним эволюционных деревьев и тд – классические задачи биоинформатики. Главным хабом является NCBI — The National Center for Biotechnology Information, www.ncbi.nlm.nih.gov. Для поиска белков со сходной последовательностью стандартно используется BLAST: blast.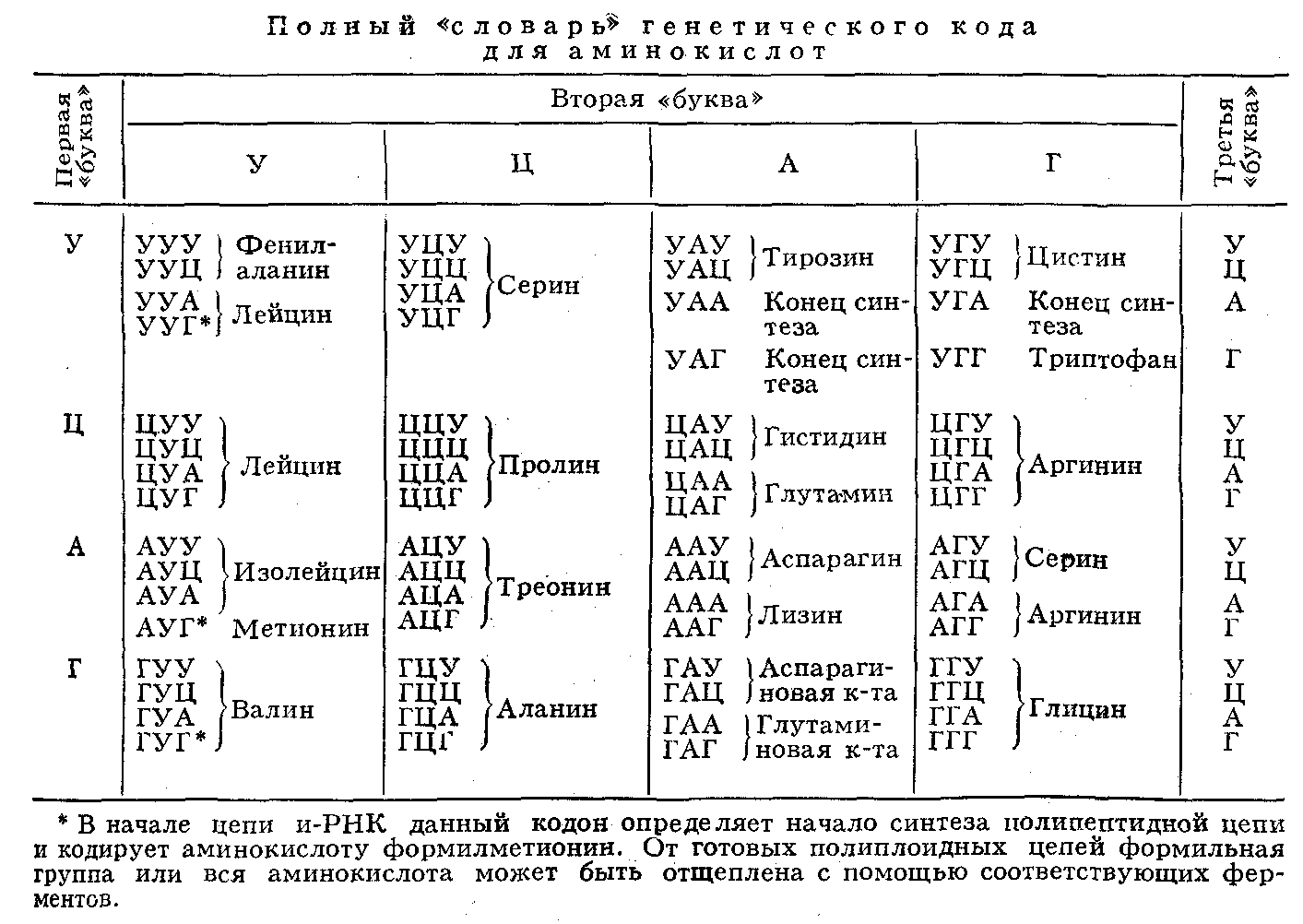 ncbi.nlm.nih.gov/Blast.cgi
ncbi.nlm.nih.gov/Blast.cgi
Предсказание растворимости белка. Речь идет о том, что если мы прочитаем геном какого-нибудь животного, определим по нему последовательности белков, переклонируем эти гены в кишечную палочку или baculovirus expression system, то окажется, что при экспрессии в этих системах примерно треть белков не будет сворачиваться в правильную структуру, и, как следствие, будет нерастворима. Тут выясняется, что большие белки на самом деле состоят из отдельных «доменов», каждый из которых представляет автономную, функциональную часть белка (несущую одну из его функций) и часто «вырезав» из гена отдельный домен, можно получить растворимый белок, определить его структуру и провести с ним опыты. Люди пытаются использовать машинное обучение (нейронные сети, SVM и прочие классификаторы), чтобы предсказывать растворимость белка, однако работает оно достаточно плохо (Гугл много чего покажет по запросу “protein solubility prediction” – есть много серверов, но по моему опыту все они работают отвратительно на моих белках). В идеале я хотел бы видеть сервис, который надежно сказал бы, где в белке находятся те самые растворимые домены, чтобы их можно было вырезать и работать с ними – такого сервиса нет.
В идеале я хотел бы видеть сервис, который надежно сказал бы, где в белке находятся те самые растворимые домены, чтобы их можно было вырезать и работать с ними – такого сервиса нет.
На уровне вторичной структуры – предсказание той самой вторичной структуры по первичной (JPred)
На уровне третичной структуры – поиск белков со сходными трехмерными структурами (DALI, en.wikipedia.org/wiki/Structural_alignment ),
Поиск структур по заданной суб-структуре. Например, у меня есть расположение трех аминокислот активного центра в пространстве. Хочу найти структуры, которые содержать такие же три аминокислоты в таком же относительном расположении, либо найти структуры белков, мутирование которых даст возможность расположить нужные аминокислоты нужным образом. (гуглить «protein substructure search»)
Предсказание потенциальной подвижности трехмерной структуры, возможных конформационных изменений – normal mode analysis, ElNemo.
На уровне четвертичной структуры – предположим, известны структуры двух белков. Известно, что они образуют комплекс. Предсказать структуру комплекса (определить, как эти два белка будут взаимодействовать посредством shape matching, например). Гуглить «protein-protein docking»
Известно, что они образуют комплекс. Предсказать структуру комплекса (определить, как эти два белка будут взаимодействовать посредством shape matching, например). Гуглить «protein-protein docking»
6. Предсказание структуры белка
Выделил эту вычислительную задачу в отдельный раздел, ибо велика она, фундаментальна и не решается в общем случае.
Экспериментально мы знаем, что если взять белок, полностью развернуть его и бросить в воду, то он свернется обратно в исходное состояние за время от миллисекунд до секунд (это утверждение справедливо по крайней мере для небольших глобулярных белков без всяких патологий). Это значит, что вся информация, необходимая для определения трехмерной структуры белка, в неявном виде содержится в его первичной последовательности, поэтому так хочется научиться предсказывать трехмерную структуру белка по последовательности аминокислот in silico! Однако эта задача в общем случае не решена до сих пор. В чем же дело? Дело в том, что в первичной последовательности отсутствует в явном виде информация, необходимая для построения структуры. Во-первых, нет информации о конформации основной цепи – а она обладает значительной подвижностью, хотя и несколько ограниченной по стерическим причинам. Плюс каждая боковая цепь каждой аминокислоты может находиться в разных конформациях, для длинных боковых групп типа аргинина, это может быть больше десятка конформаций.
Во-первых, нет информации о конформации основной цепи – а она обладает значительной подвижностью, хотя и несколько ограниченной по стерическим причинам. Плюс каждая боковая цепь каждой аминокислоты может находиться в разных конформациях, для длинных боковых групп типа аргинина, это может быть больше десятка конформаций.
Что же делать? Есть достаточно известный хабравчанам самый общий подход, называемый «молекулярная динамика» и подходящий для любых молекул и систем. Берем развернутый белок, приписываем всем атомам случайные значения скоростей, считаем взаимодействия между атомами, повторяем до тех пор, пока система не придет в стабильное состояние, соответствующее свернутому белку. Почему это не работает? Потому что современные вычислительные мощности позволяют за месяцы работы кластера считать десятки наносекунд для системы из тысяч атомов, какой является белок, помещенный в воду. Время же сворачивания белка – миллисекунды и больше, то есть вычислительных мощностей не хватает, разрыв – в несколько порядков. Впрочем, пару лет назад американцы совершили некоторый прорыв. Они использовали специальное железо, оптимизированное для векторных вычислений и после оптимизации на аппаратном уровне у них за месяцы работы машины получилось посчитать молдинамику до миллисекунд для очень маленького белка и белок свернулся, структура соответствовала экспериментально определенной ( http://en.wikipedia.org/wiki/Anton_(computer) )! Однако праздновать победу еще рано. Они взяли очень маленький (его размер раз в 5-10 меньше среднего белка) и один из самых быстросворачивающихся белков, классический модельный белок, на котором изучалось сворачивание. Для больших белков время расчетов увеличивается нелинейно и потребуются уже годы, то есть еще есть над чем работать.
Впрочем, пару лет назад американцы совершили некоторый прорыв. Они использовали специальное железо, оптимизированное для векторных вычислений и после оптимизации на аппаратном уровне у них за месяцы работы машины получилось посчитать молдинамику до миллисекунд для очень маленького белка и белок свернулся, структура соответствовала экспериментально определенной ( http://en.wikipedia.org/wiki/Anton_(computer) )! Однако праздновать победу еще рано. Они взяли очень маленький (его размер раз в 5-10 меньше среднего белка) и один из самых быстросворачивающихся белков, классический модельный белок, на котором изучалось сворачивание. Для больших белков время расчетов увеличивается нелинейно и потребуются уже годы, то есть еще есть над чем работать.
Другой подход реализован в Rosetta. Они разбивают последовательность белка на очень короткие (3-9 остатков) фрагменты и смотрят, какие конформации для этих фрагментов присутствуют в PDB, после чего запускают Монте-Карло по всем вариантам и смотрят, что получится. Иногда получается что-то годное, но в моих случаях через несколько дней работы кластера получаешь такой бублик, что возникает немой вопрос: «Кто писал их оценочную функцию, ставящую какую-то хорошую оценку вот этой загогулине?».
Иногда получается что-то годное, но в моих случаях через несколько дней работы кластера получаешь такой бублик, что возникает немой вопрос: «Кто писал их оценочную функцию, ставящую какую-то хорошую оценку вот этой загогулине?».
Есть инструменты и для моделирования вручную – можно предсказать вторичную структуру и попробовать вручную крутить ее, находя лучшую укладку. Некие гениальные люди даже выпустили игрушку FoldIt, представляющую белок схематично и позволяющую укладывать его, как-бы собирая головоломку (для интересующихся структурой – рекомендую!). Есть абсолютно официальное соревнование для предсказателей белковых структур, называемое CASP. Суть в том, что когда экспериментаторы определяют новую структуру белка, не имеющую аналогов в PDB, они могут не выкладывать ее сразу в PDB, а выставить последовательность этого белка на конкурс предсказаний CASP. Через некоторое время, когда все закончат свои предсказательные модели, экспериментаторы выкладывают свою экспериментально определенную структуру белка и смотрят, насколько хорошо сработали предсказатели. Самое интересное, что игроки FoldIt, не будучи учеными, как-то выиграли CASP у профессионалов моделирования белковых структур и предсказали структуру белка точнее. Однако даже эти успехи не позволяют утверждать, что проблема предсказания структуры белка решается – очень часто модель очень далека от реальной структуры.
Самое интересное, что игроки FoldIt, не будучи учеными, как-то выиграли CASP у профессионалов моделирования белковых структур и предсказали структуру белка точнее. Однако даже эти успехи не позволяют утверждать, что проблема предсказания структуры белка решается – очень часто модель очень далека от реальной структуры.
Все это относилось к моделированию белков ab initio, когда нет никакой априорной информации о структуре. Однако очень часто бывают ситуации, когда для некоторого белка в PDB присутствует его отдаленный родственник с уже известной структурой. Под родственником подразумевается белок с похожей первичной последовательностью. Считается, что для белков со сходством по первичной последовательности больше 30% одинаковая укладка основной цепи (хотя одинаковая укладка наблюдалась и для белков, не проявляющих никакого статистически достоверного сходства по первичной последовательности). В случае наличия гомолога (похожего белка) с известной структурой, можно сделать «гомологичное моделирование», то есть попросту «натянуть» последовательность твоего белка на известную структуру гомолога, а потом погонять минимизацию энергии, чтобы как-то все это дело утрясти. Такое моделирование показывает хорошие результаты при наличие очень близких гомологов, чем дальше гомолог – тем больше ошибка. Инструменты для гомологичного моделирования – Modeller, SwissModel.
Такое моделирование показывает хорошие результаты при наличие очень близких гомологов, чем дальше гомолог – тем больше ошибка. Инструменты для гомологичного моделирования – Modeller, SwissModel.
Можно решать и другие задачи, например, пытаться моделировать, что произойдет, если внести в белок ту или иную мутацию. Например, если заменить гидрофильную аминокислоту на поверхности белка на другую гидрофильную, то скорее всего структура белка не изменится вообще. Если заменить аминокислоту из гидрофобного ядра на другую гидрофобную, но другого размера, то скорее всего укладка белка останется той же, но слегка «съедет» на доли ангстрема. Если же заменить аминокислоту из гидрофобного ядра на заряженную, то скорее всего белок просто «взорвется» и не сможет свернуться.
Может показаться, что все не так уж и плохо и мы достаточно хорошо пониманием сворачивание белка. Да, мы понимаем кое-что, например до некоторой степени мы понимаем общие физические принципы, лежащие в основе сворачивания полипептидной цепи – они рассматриваются в замечательном учебнике Птицына и Финкельштейна «Физика белка». Однако это общее понимание не позволяет нам ответить на вопросы «Свернется ли данный белок или не свернется?», «Какая структура будет у этого белка?», «Как сделать белок с желаемой структурой?».
Однако это общее понимание не позволяет нам ответить на вопросы «Свернется ли данный белок или не свернется?», «Какая структура будет у этого белка?», «Как сделать белок с желаемой структурой?».
Вот одна из иллюстраций: мы хотим локализовать один из доменов большого белка, это стандартная задача. У нас есть фрагмент, который сворачивается и растворим, то есть это живой и здоровый белок. Мы же хотим найти его минимальную часть и начинаем методами генетической инженерии с обоих концов удалять по 2-3 аминокислоты, экспрессировать такой обрезанный белок в бактерии и смотреть его сворачиваемость экспериментально. Мы делаем десятки конструкций с такими маленькими делециями и видим такую картину – полностью растворимый и живой белок отличается от полностью мертвого и несворачивающегося на 3 аминокислоты. Повторюсь, это объективный экспериментальный результат. Проблема в том, что сейчас не существует вычислительного метода, который предсказал бы сворачиваемость белка хотя бы на уровне «да/нет» и сказал мне, где проходит граница между сворачивающимся и несворачивающимся белком, потому мы вынуждены клонировать и экспериментально проверять десятки вариантов.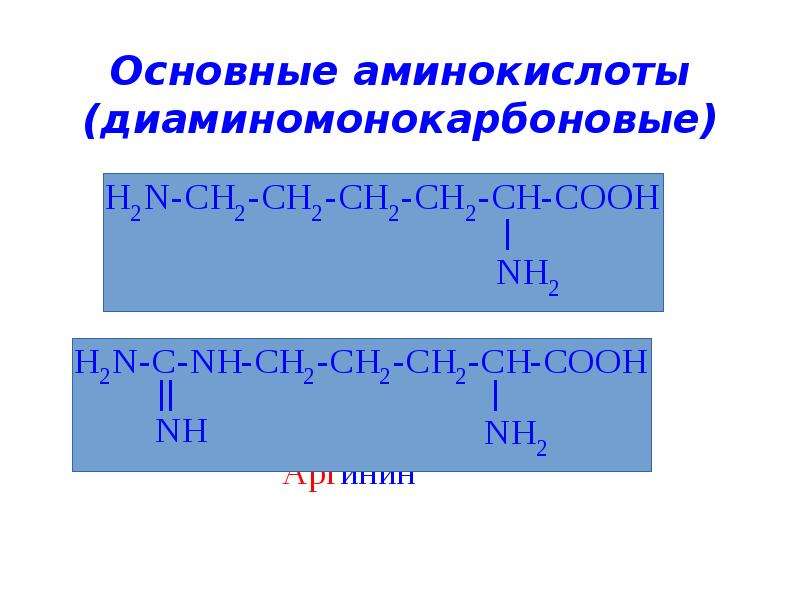 Это лишь одна из иллюстраций того, что наше понимание структуры белка весьма далеко от совершенства. Как говорил Ричард Фейнман, «Чего не могу воссоздать, того не понимаю».
Это лишь одна из иллюстраций того, что наше понимание структуры белка весьма далеко от совершенства. Как говорил Ричард Фейнман, «Чего не могу воссоздать, того не понимаю».
Так что, господа программисты, физики и математики, нам еще есть над чем работать.
На этой оптимистичной ноте разрешите откланяться, благодарю всех, кто осилил сей опус.
Для глубоко знакомства с предметной областью рекомендую следующий минимум:
1) «Физика белка» Птицын и Финкельштейн. Большую часть материала Алексей Витальевич Финкельштейн выложил в онлайн, чем и рекомендую с благодарностью воспользоваться: phys.protres.ru/lectures/protein_physics/index.html (а я утащил оттуда несколько картинок)
2) Патрушев, «Искусственные генетические системы», особенно часть II «Белковая инженерия». Есть на торрентах в формате Djvu
3) Для информации, опубликованной в биологических научных журналах, есть официальный поисковик PubMed ( www.pubmed.org ) — у него стоит попросить почитать про «protein engineering» и тому подобное.
Исправляя А-Т на Г-Ц. Создан инструмент корректирования генома по буквам
Грубо говоря, жизнь — это воспроизведение неточно самокопирующихся систем. И неточность тут так же важна, как и копирование: ошибки наследования делают живые организмы разными, а значит дают кому-то из них шанс на «апгрейд» приспособленности к условиям окружающего мира, постоянно подбрасывая эволюции новый материал для отбора. Но то, что хорошо для живого в целом, не всегда хорошо для конкретного организма — особенно если он обременён разумом и амбициями.
Изменчивость, в особенности мутационная, частенько наделяет нас помимо нашей невыносимой неповторимости ещё и некоторыми наследственными заболеваниями. Особенно заметно это на примере точечных мутаций, которыми в основном и отличаются друг от друга наши геномы.
Перед тем, как продолжить, давайте устроим себе короткий экскурс в молекулярную биологию. Каждая из двух цепей спирали ДНК состоит из нуклеотидов. Самая важная для хранения информации часть нуклеотида — его азотистое основание. Всего этих оснований четыре штуки: аденин (А), тимин (Т), гуанин (Г) и цитозин (Ц). Эти основания из двух разных цепей развёрнуты к центру двойной спирали, где аденин дополняет тимин (и наоборот), образуя с ним пару А-Т; подобные же отношения связывают и гуанин с цитозином, формирующих пару Г-Ц. Именно этой азбукой и записывается информация об аминокислотной последовательности всех белков нашего организма.
Всего этих оснований четыре штуки: аденин (А), тимин (Т), гуанин (Г) и цитозин (Ц). Эти основания из двух разных цепей развёрнуты к центру двойной спирали, где аденин дополняет тимин (и наоборот), образуя с ним пару А-Т; подобные же отношения связывают и гуанин с цитозином, формирующих пару Г-Ц. Именно этой азбукой и записывается информация об аминокислотной последовательности всех белков нашего организма.
Из-за самых разных факторов — от обычного теплового движения до рентгеновского излучения и веществ-мутагенов — основания могут отрываться или изменяться химически. Обычно клеточная ремонтная бригада — система репарации — отлично справляется со своей работой и быстро восстанавливает повреждённое или оторванное основание, используя в качестве шаблона вторую, комплементарную цепь. Однако время от времени ферменты системы репарации допускают ошибки. Как результат — в геноме происходят точечные замены оснований. Из-за них и возникают хорошо известные генетикам однонуклеотидные полиморфизмы или SNP (сокр. от single nucleotide polymorphism) — «однобуквенные» различия между последовательностями нуклеотидов у отдельных индивидуумов. Именно на их долю приходится 90% наших генетических отличий друг от друга.
Из-за них и возникают хорошо известные генетикам однонуклеотидные полиморфизмы или SNP (сокр. от single nucleotide polymorphism) — «однобуквенные» различия между последовательностями нуклеотидов у отдельных индивидуумов. Именно на их долю приходится 90% наших генетических отличий друг от друга.
Подавляющая часть точечных мутаций никак не сказывается на добром здравии организма. Большинство из них приходится на эгоистичные и повторяющиеся последовательности генома, которых у нас абсолютное большинство. Кроме того, наш генетический код триплетен, то есть каждая аминокислота кодируется тремя буквами-нуклеотидами и вырожден — то есть каждой аминокислоте соответствует набор из нескольких триплетов. Как следствие, далеко не каждая нуклеотидная замена приводит к аминокислотной замене в структуре белка. И, естественно, не любая аминокислотная замена приведёт к полной поломке белка или драматическому изменению его активности. Но если такая мутация всё-таки влияет на функциональность белка — последствия могут быть самыми серьёзными.
Взять ту же самую серповидно-клеточную анемию, (да-да, ту самую, что помимо кучи проблем придаёт своим носителям ещё и устойчивость к малярии). У её невезучих обладателей в седьмом кодоне гена β-глобина аденин заменён на тимин. Единичная А-Т мутация приводит к тому, что глутаминовая кислота, стоящая в 7-м положении гемоглобина, меняется на валин. Молекулы такого дефектного гемоглобина — его называют гемоглобин S или HbS — легко слипаются друг с другом, образуя длинные тяжи, искажающие форму эритроцитов. Такие серповидные эритроциты живут намного меньше своих нормальных двояковогнутых братьев, практически неспособны переносить кислород, а также полностью теряют свою упругость, из-за чего-то и дело застревают в мелких капиллярах, приводя к их закупорке.
Серповидно-клеточная анемия — самый распространённый, но, к несчастью, не единственный пример наследственного заболевания связанного с точечными мутациями. С однонуклеотидными мутациями ассоциирован ещё множество других наследственных заболеваний, включая целый набор анемий, некоторые формы болезней Альцгеймера и Паркинсона, и даже такие чудовищные, но, к счастью, сравнительно редкие патологии, как прогерия (преждевременное старение) и фатальная семейная бессонница.
Поскольку все эти заболевания связаны с точечными мутациями в единичных генах, исправив сломанный ген, мы можем исправить и проблему, вылечив пациента или как минимум существенно облегчив его положение. Только для этого нам нужен специальный эффективный редактор азотистых оснований, способный работать в живом человеке.
На этом месте наш просвещённый читатель наверняка воскликнет: А чего тут изобретать-то! У нас же есть CRISPR-Cas9! И будет по-своему прав. Известнейшая ферментная система, о которой сейчас не говорит только ленивый, действительно в большинстве случаев может исправлять точечные мутации. Но делает она это довольно рискованно — разрезая спираль ДНК по обеим цепям.
Single-molecule movie of DNA search and cleavage by CRISPR-Cas9. pic.twitter.com/3NQxmbvzJF
— hnisimasu (@hnisimasu) November 10, 2017
Такое серьезное повреждение ДНК активирует сразу две системы репарации ДНК. Первая — система гомологичной рекомбинации. Она восстанавливает целостность ДНК, используя в качестве образца неповреждённую последовательность, максимально похожую на повреждённую. При этом мы можем подсунуть клетке в качестве шаблона нужную нам, отредактированную последовательность, и она восстановит разорванный участок так, как нам это нужно. Вот, собственно, чего мы добиваемся. Но тут всё не заканчивается — параллельно пойдёт крайне вредный для нас процесс негомологичного соединения концов, во время которого края разорванной ДНК будут соединены друг с другом случайным образом. При этом могут быть слиты воедино вообще, никак друг с другом не связанные куски ДНК, что приведёт к перетасовке фрагментов ДНК между хромосомами.
Она восстанавливает целостность ДНК, используя в качестве образца неповреждённую последовательность, максимально похожую на повреждённую. При этом мы можем подсунуть клетке в качестве шаблона нужную нам, отредактированную последовательность, и она восстановит разорванный участок так, как нам это нужно. Вот, собственно, чего мы добиваемся. Но тут всё не заканчивается — параллельно пойдёт крайне вредный для нас процесс негомологичного соединения концов, во время которого края разорванной ДНК будут соединены друг с другом случайным образом. При этом могут быть слиты воедино вообще, никак друг с другом не связанные куски ДНК, что приведёт к перетасовке фрагментов ДНК между хромосомами.
Конечно, тут клетку можно понять — двуцепочечный разрыв ДНК — дело серьёзное, и нужно срочно принимать какие-то меры, пусть даже и рискованные. Но нас с вами этот опасный побочный процесс совсем не радует, тем более что задача у нас скромная — всего-то заменить один нуклеотид на другой. Может быть здесь можно обойтись и без двуцепочечных разрывов? Определённо, можно.
В конце этого ноября команда гарвардских исследователей заявила, что их многолетняя работа наконец увенчалась успехом — они создали с редактор азотистых оснований успешно и безопасно исправляющий пару А-Т на Г-Ц.
Тут сам собой возникает вопрос: а с чего это исследователи взялись именно за эту нуклеотидную пару? Не вдаваясь в унылые биохимические подробности, скажу, что химические особенности азотистых оснований делают особенно лёгким именно превращение цитозина в тимин. Это происходит сразу за счёт двух химических реакций — дезаминирования цитозина до урацила и дезаминирования очень распространённого в ДНК 5-метилцитозина до тимина (особенно дотошные читатели могут изучить подробности этих превращений в классическом обзоре).
В коллаже использованы иллюстрации chromatos / Фотодом / ShutterstockПо этим причинам, конверсия цитозина в тимин стала настоящий горячей точкой мутагенеза — каждый день в каждой клетке нашего тела от 100 до 500 цитозинов спонтанно превращаются в тимины. Целых 48% всех SNP-патологий человека возникают по причине превращения пары Г-Ц в А-Т! И, соответственно, могут быть исправлены обратной конверсией. Поэтому безопасный и надёжный молекулярный редактор, переписывающий А-Т в Г-Ц — давняя и вожделенная мечта учёных и врачей-генетиков.
Целых 48% всех SNP-патологий человека возникают по причине превращения пары Г-Ц в А-Т! И, соответственно, могут быть исправлены обратной конверсией. Поэтому безопасный и надёжный молекулярный редактор, переписывающий А-Т в Г-Ц — давняя и вожделенная мечта учёных и врачей-генетиков.
Для создания белка-редактора был использован традиционный для биоинженерии подход. Две белковых последовательности соединили вместе гибким переходником в химерную конструкцию. За основу был взят фермент аденин-деаминаза TadA кишечной палочки, умеющий отрезать аминогруппу от азотистого основания аденина. К нему через гибкий переходник длиной в пару десятков аминокислотных остатков пришили уже знакомую нам Cas9, только лишённую каталитической функции. Такая версия Cas9, так же как и нормальная версия нуклеазы, распознаёт место своей посадки на ДНК с помощь гидовой-РНК, но ни на какие двуцепочечные разрывы не способна, поэтому её обозначают dCas9 (от dead — мёртвый). Задумка учёных была довольно очевидна — dCas9 наводится на место редактирования гидовой РНК, притаскивая с собой аденин-деаминазу. Деаминаза отщепляет от аденина из А-Т пары аминогруппу, превращая его в азотистое основание инозин. В норме инозин не встречается в ДНК, и распознаётся системами репарации как гуанин. Таким образом мы получаем некомплиментарную пару И~Т, которая в ходе репарации и следующего раунда репликации меняется на традиционную и желаемую нами Г-Ц.
Деаминаза отщепляет от аденина из А-Т пары аминогруппу, превращая его в азотистое основание инозин. В норме инозин не встречается в ДНК, и распознаётся системами репарации как гуанин. Таким образом мы получаем некомплиментарную пару И~Т, которая в ходе репарации и следующего раунда репликации меняется на традиционную и желаемую нами Г-Ц.
Нужно признать, что большинство ферментов, связанных вместе и ставших частью химеры, стремительно снижают свою активность. Не обошла эта судьба и нашу деаминазу. Биоинженерная конструкция работала очень плохо, поэтому для её совершенствования было проведено множество раундов искусственной эволюции. Для этого учёные вносили различные варианты генов белка-редактора в культуру бактерий, выращиваемых на среде с антибиотиком. При этом у бактерий так же были гены устойчивости к антибиотикам, но они были почти полностью заблокированы однонуклеотидными мутациями. По задумке ушлых учёных — чем активнее работала белковая химера-редактор, тем большее преимущество получала её бактерия-носитель, вновь активируя с её помощью жизненно необходимые гены резистентности к антибиотику.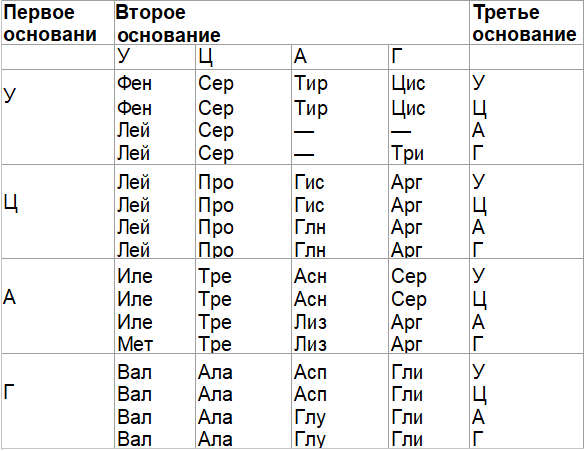 Так, отобрав самые быстро растущие колонии бактерий, из них можно было выделить гены наиболее эффективных белков-редакторов.
Так, отобрав самые быстро растущие колонии бактерий, из них можно было выделить гены наиболее эффективных белков-редакторов.
Таким манером примерно за год неутомимые гарвардские учёные вместе со своими одноклеточными коллегами создали аж несколько десятков белков-редакторов, каждый — со своими особенностями работы. Оставалось лишь выбрать тот, что больше всего подходил для работы на человеческих клетках и проверить его в действии. Это было сделано на культурах клеток человека, в которых полученная система бойко исправляла однонуклеотидные мутации, ответственные за развитие наследственного гемохроматоза и персистенции фетального гемоглобина с эффективностью 28% и 29%. На первый взгляд, эти цифры не слишком впечатляют, даже в сравнении с предыдущими достижениями гарвардской команды. Но главное другое — ни одним из методов не удалось выявить случаев ложного срабатывания редактора. То есть молекулярный механизм оказался ещё и точным — по-видимому, в корректируемые матрицы не была внесена ни одна новая мутация. Всё это говорит о крайней безопасности метода, и делает его предпочтительным для решения медицинских задач, связанных с исправлением точечных генных полиморфизмов.
Всё это говорит о крайней безопасности метода, и делает его предпочтительным для решения медицинских задач, связанных с исправлением точечных генных полиморфизмов.
Так уж получилось, что жизнь может преуспеть лишь постоянно изменяя свою форму. В дикой надежде угадать нужды завтрашнего дня эволюция создаёт тысячи генных вариантов без оглядки на цену, которую, возможно, придётся заплатить их носителям. Единственная нуклеотидная замена в неподходящем месте легко перечеркивает наши планы, здоровье и саму жизнь. Но времена меняются. Прямо сейчас создаются фантастические молекулярные инструменты, которые очень скоро позволят обжаловать даже самые суровые генетические приговоры.
Дмитрий Лебедев
Генетический код
Биология Генетический код
просмотров — 143
В любом данном участке ДНК только одна из двух нитей ДНК кодирует аминокислоты, в связи с этим код — ϶ᴛᴏ последовательность нуклеотидов, а не пар нуклеотидов. Генетический код имеет следующие свойства:
Генетический код имеет следующие свойства:
1. Генетический код читается группами по три нуклеотида, ᴛ.ᴇ. код триплетный. Каждый триплет кодирует аминокислоту, каждый триплет принято называть кодоном.
2. Основные закономерности организации генетического кода были открыты с помощью генетического анализа района II фага Т6. В 1961 ᴦ. Ф. Крик и его коллеги показали, что код должен читаться неперекрывающимися триплетами с фиксированной стартовой точки.
а) неперекрывание подразумевает, что каждый кодон состоит из трех нуклеотидов и каждый последующий кодон представлен следующими тремя нуклеотидами.
б) Фиксированная стартовая точка означает, что считывание начинается на одном конце и завершается на другом; различные части кодирующей последовательности не могут считываться независимо друг от друга.
Началом трансляции любого гена является кодон AUG. В конце гена обязательно стоят кодоны UAA, UAG или UGA, которые не кодируют аминокислот и являются сигналами на окончание синтеза белка — стоп-кодоны. Для повышения надежности процесса терминации стоп-кодоны обычно дублируются. Первым при этом, как правило, выступает кодон UAA (основной терминирующий триплет), а вслед за ним на очень близком расстоянии в той же рамке считывания следует один из запасных терминирующих триплетов — UAG или UGA.
Для повышения надежности процесса терминации стоп-кодоны обычно дублируются. Первым при этом, как правило, выступает кодон UAA (основной терминирующий триплет), а вслед за ним на очень близком расстоянии в той же рамке считывания следует один из запасных терминирующих триплетов — UAG или UGA.
Таблица –Соответствие кодонов генетического кода аминокислотам белка
| Первая буква в кодоне (5′) | Вторая буква в кодоне | Третья буква в кодоне (3′) | |||
| U | С | А | G | ||
| U | Фен (F) Фен (F) Лей (L) Лей (L) | Сер (S) Сер (S) Сер (S) Сер (S) | Тир (Y) Тир (Y) Stop Stop | Цис (С) Цис (С) Stop Трп (W) | U с А G |
| С | Лей (L) Лей (L) Лей (L) Лей (L) | Про (Р) Про (Р) Про (Р) Про (Р) | Гис (Н) Гис (Н) Глн (Q) Глн (Q) | Apr (R) Apr (R) Apr (R) Apr (R) | U С А G |
| А | Иле (I) Иле (I) Иле (I) Мет (М) | Тре (Т) Тре (Т) Тре (Т) Тре (Т) | Ach(N) Ach(N) Лиз (К) Лиз (К) | Сер (S) Сер (S) Apr (R) Apr (R) | U С А G |
| G | Вал(У) Вал(У) Вал(У) Вал(У) | Ала (А) Ала (А) Ала (А) Ала (А) | Асп (D) Асп (D) Глу (Е) Глу (Е) | Гли (G) Гли (G) Гли (G) Гли (G) | U С А G |
Примечание
U — урацил, С — цитозин, А — Аденин, G — гуанин, F, L, I и т. д. — однобуквенные сокращения названий аминокислот, Фен, Сер и т.д. -трехбуквенные сокращения. Кодоны UAA, UAG, UGA — не кодируют аминокислот. Эти кодоны являются сигналами терминации трансляции — стоп-кодонами
д. — однобуквенные сокращения названий аминокислот, Фен, Сер и т.д. -трехбуквенные сокращения. Кодоны UAA, UAG, UGA — не кодируют аминокислот. Эти кодоны являются сигналами терминации трансляции — стоп-кодонами
в) В случае если генетический код считывается неперекрывающимися триплетами, есть только три возможности транслирования нуклеотидной последовательности в аминокислотную, в зависимости от стартовой точки. Эти три возможности называют рамками считывания.
Мутация, в результате которой инсертируется или делетируется один нуклеотид и изменяется рамка считывания всей последующей последовательности, принято называть сдвигом рамки. Поскольку последовательность новой рамки считывания полностью отлична от первоначальной, вся аминокислотная последовательность будет измененной ниже мутации. Функция такого белка полностью утрачена.
Дополнение
Проблема кодирования в молекулярной биологии была впервые поставлена Г. Гамовым еще в начале 50х годов, ᴛ. ᴇ. задолго до открытия самой мРНК. Размышляя над тем, как линейная последовательность четырех различных нуклеотидов может определить последовательность двадцати разных аминокислот в белке, Гамов предположил, что генетический код является триплетным. Он же поставил вопросы и о других свойствах генетического кода: перекрываемости, запятых между кодонами, вырожденности.
ᴇ. задолго до открытия самой мРНК. Размышляя над тем, как линейная последовательность четырех различных нуклеотидов может определить последовательность двадцати разных аминокислот в белке, Гамов предположил, что генетический код является триплетным. Он же поставил вопросы и о других свойствах генетического кода: перекрываемости, запятых между кодонами, вырожденности.
3. Генетический код является вырожденным, в том смысле, что одной аминокислоте может соответствовать несколько кодонов (Таблица). При этом, кодоны используются не с одинаковой частотой. К примеру, у дрозофилы, в результате параллельного изучения последовательностей кодонов в генах и аминокислот, кодированных ими, при этом суммарная длина генов соответствовала 269 т.п.н., было показано, что кодоны используются с разными частотами.
Дополнение
В 1968 году за открытие и интерпретацию генетического кода и его функции в белковом синтезе Нобелевская премия была присуждена Р. Холли, X. Г. Хоране и М.В. Ниренбергу.
4. Генетический код универсален, в том смысле, что определённому кодону соответствует определённая аминокислота. К примеру, AUG-кодон кодирует метионин у любого организма. При этом, по мере расширения круга объектов молекулярной генетики стали накапливаться исключения, сделавшие код «квазиуниверсальным». Касается это прежде всего митохондриальных геномов.
Читайте также
Ранее мы подчёркивали, что нуклеотиды имеют важную для формирования жизни на Земле особенность – при наличии в растворе одной полинуклеотидной цепочки спонтанно происходит процесс образования второй (параллельной) цепочки на основании комплементарного соединения… [читать подробенее]
Синтез белка в клетках эукариот Лекция 6 Известно, что ДНК состоит из 4-х видов нуклеотидов (А, Г, Т, Ц). Математические расчеты показывают, что для кодирования одно аминокислоты требуется более одного нуклеодида, так как в белках обнаружено более 20 различных… [читать подробенее]
Нуклеиновые кислоты, их виды, строение, локализация в клетке, значение. Строение, свойства и функции хромосом. Хромосомы, их классификация по месту расположения центромеры. Кариотип. Идеограмма. Хромосомы, органоиды ядра клетки, определяющие… [читать подробенее]
Биосинтез белков Биосинтез белков является важнейшим процессом анаболизма. Все признаки, свойства и функции клеток и организмов определяются в конечном итоге белками. Белки недолговечны, время их существования ограничено. В каждой клетке постоянно синтезируются… [читать подробенее]
Одно из более существенных достижений молекулярной генетике заключается в установлении малых размеров участка гена, передающихся при кроссинговере ( в молекулярной генетики вместо термина «кроссинговера» принят термин «рекомбинация», который все еще начинают… [читать подробенее]
Ген – фрагмент геномной нуклеиновой кислоты. Свойства генов и их функции. В начале 50-х годов было доказано, что материальной единицей наследственности и изменчивости является ген, который имеет определенную структурно-функциональную организацию. По современному… [читать подробенее]
Генетика – наука о воспроизведении живых существ, наследственности и изменчивости, о генотипах живых существ. Генетический код — свойственный всем живым организмам способ кодирования аминокислотной последовательности белков при помощи последовательности… [читать подробенее]
Генетический код – это система записи информации о последовательности расположения аминокислот в белках с помощью последовательности расположения нуклеотидов в молекуле ДНК. Свойства генетического кода: 1.Код триплетен – каждая аминокислота зашифрована… [читать подробенее]
Репарация двунитевых разрывов ДНК и глобальный клеточный ответ Способность к синтезу ДНК на поврежденной матрице Гены репарации ДНК, связанные с различными наследственными болезнями человека Коррекция неспаренных оснований MSh3, MSH6, MLh2 – наследственный… [читать подробенее]
Ген как дискретная единица наследственности СТРОЕНИЕ, СВОЙСТВА И ФУНКЦИИ ГЕНОВ.Одним из фундаментальных понятий генетики на всех этапах ее развития было понятие единицы наследственности. В 1865 году основоположник генетики (науки о наследственности и изменчивости)… [читать подробенее]
Доктор Маргарет Окли Дейхофф
Доктор Маргарет Окли ДейхоффБиологический проект> Биохимия> Химия аминокислот
Доктор Маргарет Окли Дейхофф Записка о докторе Дейхоффе
Биофизический
Общество
Происхождение однобуквенного код для аминокислот
Происхождение однобуквенного кода для аминокислот происходит от исторический интерес, и, по сути, эта история может помочь студенту изучить код.Причина появления кода достаточно проста — в самом начале В дни биоинформатики самые быстрые компьютеры были довольно неуклюжими. Доктор Маргарет Окли Дейхофф, возможно, основательница области биоинформатики, сократил код с трехбуквенного обозначения до однобуквенного кода в попытке уменьшить размер файлов данных, необходимых для описания последовательности аминокислот в протеине. Список аминокислот, три буквы и однобуквенный код, и объяснение выбора однобуквенного кода приводится ниже.Обратите внимание, что в белках обычно содержится 20 аминокислот, и 26 букв в алфавите. В результате используется большая часть букв.
Чтобы разработать однобуквенный код для аминокислот, доктор Дейхофф попытался чтобы код было как можно проще запомнить. Конечно, если имя Каждая аминокислота начинается с другой буквы, код действительно будет простым. Для 6 аминокислот первая буква названия уникальна, поэтому код простой.Это:
| Аминокислота | Трехбуквенный код | Однобуквенный код | Пояснение |
Цистеин | Cys Его Иль Встретил Ser Вал | C H Я M S V | Первая буква имени Первая буква имени Первая буква имени Первая буква имени Первая буква имени Первая буква имени |
Для других аминокислот первая буква имени не уникальна для одна аминокислота, поэтому Dr.Dayhoff присвоил буквы A, G, L, P и T. аминокислоты аланин, глицин, лейцин, пролин и треонин соответственно, которые встречаются в белках чаще, чем другие аминокислоты, имеющие те же первые буквы.
| Аминокислота | 3-хбуквенный код | Однобуквенный код | Пояснение |
| Аланин Глицин Лейцин Пролин Треонин | Ала Gly Leu Pro Thr | A G L P Т | Первая буква имени Первая буква имени Первая буква имени Первая буква имени Первая буква имени |
Некоторые другие аминокислоты фонетически наводят на размышления.
Что касается оставшихся 5 аминокислот, доктор Дэйхофф пытался найти легко запоминающаяся связь между одной буквой и аминокислотой. Она назначила буквам аспарагиновую кислоту, аспарагин, глутаминовую кислоту и глутамин. D, N, E и Q соответственно, отмечая, что D и N ближе к началу алфавит, чем E и Q, и что Asp меньше Glu, а Asn меньше чем Gln.
К тому времени, как доктор Дейхофф добрался до лизина, осталось не так уж много букв, поэтому она использовала букву K, объяснив, что K по крайней мере рядом с L в алфавите.
| Аминокислота | 3-хбуквенный код | Однобуквенный код | Пояснение |
| Лизин | Lys | K |
|
Заметка о Dr.Маргарет Окли Дэйхофф (1925-1983)
Профессиональный некролог
Д-р Маргарет Окли Дейхофф была профессором Медицинского университета Джорджтауна. Центр и известный биохимик-исследователь в Национальном фонде биомедицинских исследований где она была пионером в применении математики и вычислительных методов в области биохимии. Доктор Дайхофф посвятила свою карьеру применению развивающиеся вычислительные технологии для поддержки достижений в биологии и медицине, прежде всего создание баз данных белков и нуклеиновых кислот и инструментов для опросить базы данных.Ее докторская степень была получена в Колумбийском университете. на химическом факультете, где она разработала вычислительные методы для расчета энергии молекулярного резонанса нескольких органических соединений. Она защитила докторскую учится в Институте Рокфеллера (ныне Университет Рокфеллера) и в университете штата Мэриленд и присоединился к недавно созданному Национальному фонду биомедицинских исследований. в 1959 г.
Работа доктора Дейхофф с белками началась в 1961 году, когда она разработала инструменты для помощь химикам-белкам в определении аминокислотных последовательностей за счет автоматического перекрывающиеся последовательности пептидов.Она продолжала инициировать «Атлас последовательности и структуры белков », а также для разработки многих используемых инструментов сегодня в проектировании и использовании баз данных. В 1980 году доктор Дейхофф разработал онлайновая система баз данных, к которой можно получить доступ по телефонной линии, первая База данных последовательностей доступна для опроса удаленными компьютерами. Доктор Маргарет Окли Дейхофф, основательница области биоинформатики, умерла раньше поле было признано отдельной областью для исследования.Она была, действительно, первопроходец.
Доктор Дайхофф был чрезвычайно активен в Биофизическом обществе и служил общество как его секретарь и президент. Одним из ее интересов было в расширении возможностей женщин для успешного карьерного роста в науке. Она хорошо знала о многих проблемах, с которыми сталкиваются женщины в науке, и работала трудно поощрять и наставлять женщин в научной карьере. Поэтому это соответствует тому, что награда Margaret Oakley Dayhoff была учреждена для поощрения молодых женщин к участию в конкурсе. карьера в научных исследованиях.Эта награда предназначена для женщин очень многообещающие, которые еще не достигли высокого признания в структура академического сообщества. Он управляется через Биофизический Общество и кандидаты оцениваются по достижениям и перспективам в областях внутри цель Биофизического общества.
Закрыть окно
Биологический проект> Биохимия> Химия аминокислот
Биологический проект
Департамент биохимии и молекулярной биохимии Биофизика
Университет Аризоны
25 августа 2003 г.
Связаться с командой разработчиков
http: // www.biology.arizona.edu
Все права защищены © 2003. Все права защищены.
Произошла ошибка при настройке пользовательского файла cookie
Этот сайт использует файлы cookie для повышения производительности. Если ваш браузер не принимает файлы cookie, вы не можете просматривать этот сайт.
Настройка вашего браузера для приема файлов cookie
Существует множество причин, по которым cookie не может быть установлен правильно.Ниже приведены наиболее частые причины:
- В вашем браузере отключены файлы cookie. Вам необходимо сбросить настройки своего браузера, чтобы он принимал файлы cookie, или чтобы спросить вас, хотите ли вы принимать файлы cookie.
- Ваш браузер спрашивает вас, хотите ли вы принимать файлы cookie, и вы отказались. Чтобы принять файлы cookie с этого сайта, нажмите кнопку «Назад» и примите файлы cookie.
- Ваш браузер не поддерживает файлы cookie. Если вы подозреваете это, попробуйте другой браузер.
- Дата на вашем компьютере в прошлом.Если часы вашего компьютера показывают дату до 1 января 1970 г., браузер автоматически забудет файл cookie. Чтобы исправить это, установите правильное время и дату на своем компьютере.
- Вы установили приложение, которое отслеживает или блокирует установку файлов cookie. Вы должны отключить приложение при входе в систему или проконсультироваться с системным администратором.
Почему этому сайту требуются файлы cookie?
Этот сайт использует файлы cookie для повышения производительности, запоминая, что вы вошли в систему, когда переходите со страницы на страницу.Чтобы предоставить доступ без файлов cookie потребует, чтобы сайт создавал новый сеанс для каждой посещаемой страницы, что замедляет работу системы до неприемлемого уровня.
Что сохраняется в файле cookie?
Этот сайт не хранит ничего, кроме автоматически сгенерированного идентификатора сеанса в cookie; никакая другая информация не фиксируется.
Как правило, в файлах cookie может храниться только информация, которую вы предоставляете, или выбор, который вы делаете при посещении веб-сайта.Например, сайт не может определить ваше имя электронной почты, пока вы не введете его. Разрешение веб-сайту создавать файлы cookie не дает этому или любому другому сайту доступа к остальной части вашего компьютера, и только сайт, который создал файл cookie, может его прочитать.
Запись последовательностей пептидов и белков
Запись последовательностей пептидов и белковВведение в структуру белка
Запись последовательностей пептидов и белков
Первичная структура (или последовательность) пептида или белка: всегда пишется, начиная с аминоконца слева и продвигаясь к карбоксильный конец.Если вся последовательность не умещается в одной строке, это просто продолжается во второй строке, по-прежнему следуя слева направо, от амино-карбокси-конца соглашение.
Аминокислотные последовательности могут быть записаны с использованием трех буквенных обозначений. код или однобуквенный код. Точное формирование последовательностей зависит от приложения; к условные однобуквенные коды всегда пишутся с заглавной буквы.
Вот коды для каждой аминокислоты:
| Аминокислота | Трехбуквенный код | 1 Буквенный код | Аминокислота | Трехбуквенный код | 1 буквенный код | |
|---|---|---|---|---|---|---|
| Аланин | Ала | А | лейцин | лей | л | |
| Аргинин | Арг | R | Лизин | Lys | К | |
| аспарагин | Asn | N | метионин | встретил | M | |
| аспартат | Асп | D | фенилаланин | Phe | F | |
| Цистеин | Cys | С | Пролин | Pro | -п. | |
| Гистидин | Его | H | Серин | Ser | S | |
| Изолейцин | Иль | I | Треонин | Thr | т | |
| Глютамин | Gln | Q | Триптофан | Trp | Вт | |
| Глутамат | Glu | E | Тирозин | Тир | Y | |
| Глицин | Gly | G | Валин | Вал | В |
Примеры первичных конструкций:
Пример | Три буквенный код | Один Буквенный код | |
| Малый пептид (8 остатков) | AspIleGluPheArgValLeuHis | DIEFRVLH | |
| лизоцим * (129 остатков) * из куриного яичного белка | LYS VAL PHE GLY ARG CYS GLU LEU ALA ALA ALA MET LYS ARG HIS GLY LEU ASP ASN TYR ARG GLY TYR SER LEU GLY ASN TRP VAL CYS ALA ALA LYS PHE GLU SER ASN PHE ASN THR GLN ALA THR ASN ARG ASN THR ASP GLY SER THR ASP TYR GLY ILE LEU GLN ILE ASN SER ARG TRP TRP CYS ASN ASP GLY ARG THR PRO GLY SER ARG ASN LEU CYS ASN ILE PRO CYS SER ALA LEU LEU SER SER ASP ILE THR ALA SER VAL ASN CYS ALA LYS LYS ILE VAL SER ASP GLY ASN GLY MET ASN ALA TRP VAL ALA TRP ARG ASN ARG CYS LYS GLY THR ASP VAL GLN ALA TRP ILE ARG GLY CYS ARG LEU | KVFGRCELAA AMKRHGLDNY RGYSLGNWVC AAKFESNFNT QATNRNTDGS TDYGILQINS RWWCNDGRTP GSRNLCNIPC SALLSSDITA SVNCAKKIVS DGNGMNAWVA WRNRCKGTDV QAWIRGCRL | |
Авторское право 1998, 1999, 2007 Фрэнк Р.Горга; Страница поддерживается F.R. Горга; Последнее обновление: 12 марта 2007 г.
Сокращенные символы для аминокислот
Сокращенные символы для аминокислот| Индекс | Учебный план | Расписание | Учебные пособия | Вычислительная техника | Ссылки | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
КОРОТКИЕ СИМВОЛЫ АМИНОКИСЛОТ[1-буквенные символы обычно используются последовательно данные]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Индекс | Учебный план | Расписание | Учебные пособия | Вычислительная техника | Ссылки |
Обновлено 27.08.04 пользователем [email protected]
Однобуквенный код аминокислот
Однобуквенный код аминокислотыОднобуквенный код аминокислоты
В таблице ниже указано:
• Имена 20 распространенных аминокислоты |
• Соответствующее трехбуквенное сокращение |
• Однобуквенный код для аминокислота |
Аланин | Ала | А |
Аргинин | Арг. | R |
Аспарагин | Асн | N |
Аспарагиновая кислота | Асп | D |
Цистеин | Cys | С |
Глютамин | Gln | квартал |
Глутаминовая кислота | Glu | E |
Глицин | Гли | г |
Гистидин | Его | H |
Изолейцин | Иль | Я |
лейцин | лей | л |
Лизин | Lys | К |
метионин | Встреча | м |
Фенилаланин | Phe | Ф |
Proline | Pro | -П |
Серин | Ser | S |
Треонин | Thr | т |
Триптофан | Trp | Вт |
Тирозин | тир | Я |
Валин | Вал | В |
АМИНОКИСЛОТ
ТЕХНИЧЕСКИЙ ЛИСТ АМИНОКИСЛОТАМИНОКИСЛОТ ПО МОЛЕКУЛЯРНОЙ МАССЕ
| Триптофан | 186.21 | Тирозин | 163,18 | Аргинин | 156,20 | Фенилаланин | 147,18 |
| Гистидин | 137,15 | Метионин | 131,21 | Глутаминовая кислота | 129,12 | Лизин | 128.18 |
| Глютамин | 128,14 | Аспарагиновая кислота | 115,09 | Аспарагин | 114,11 | Лейцин | 113,17 |
| Изолейцин | 113,17 | Цистеин | 103,14 | Треонин | 101.11 | Валин | 99,14 |
| Пролин | 97,12 | Серин | 87,08 | Аланин | 71,08 | Глицин | 57.06 |
Аминокислоты, перечисленные в алфавитном порядке
| Аланин | Ала | Аргинин | Арг | аспарагин | Asn | Аспарагиновая кислота | Asp |
| Цистеин | Cys | Глютамин | Gln | Глутаминовая кислота | Glu | Глицин | Гли |
| Гистидин | His | Изолейцин | Иль | лейцин | лей | Лизин | Лиз |
| Метионин | Мет | Фенилаланин | Phe | Proline | Pro | Серин | Ser |
| Треонин | Thr | Триптофан | Трп | Тирозин | Тир | Валин | Вал |
АМИНОКИСЛОТ ПО ОДНОБуквенному коду
| Аланин | A | Цистеин | C | Аспарагиновая кислота | D | Глутаминовая кислота | E |
| Фенилаланин | F | Глицин | G | Гистидин | H | Изолейцин | I |
| Лизин | K | Лейцин | л | Метионин | M | Аспарагин | N |
| Пролин | P | Глютамин | Q | Аргинин | R | Серин | S |
| Треонин | T | Валин | В | Триптофан | Вт | Тирозин | Y |
АМИНОКИСЛОТА ПО ХАРАКТЕРИСТИКАМ БОКОВОЙ ЦЕПИ
| Алифатический неполярный | Аланин |
| | Глицин |
| | Лейцин |
| | Изолейцин |
| | |
| Алифатический полярный | Треонин |
| | |
| Циклический неполярный | Фенилаланин |
| | Proline |
| | |
| Циклический полярный | Триптофан |
| | Тирозин |
| | |
| Серосодержащий | метионин |
| | Цистеин |
| | |
| Катионный | Аргинин |
| | Лизин |
| | Гистидин |
| | |
| Анионный | Аспарагиновая кислота |
| | Аспарагин |
| | Глутаминовая кислота |
| | Глютамин |
АМИНОКИСЛОТА ПО ЧАСТОТЕ ОБНАРУЖЕНА В БЕЛКЕ
| Аланин | 9.0% | Глицин | 7,5% | Лейцин | 7,5% | Серин | 7,1% |
| Лизин | 7,0% | Валин | 6,9% | Глутаминовая кислота | 6,2% | Треонин | 6,0% |
| Аспарагиновая кислота | 5.5% | Аргинин | 4,7% | Пролин | 4,6% | Изолейцин | 4,6% |
| Аспарагин | 4,4% | Глютамин | 3,9% | Тирозин | 3,5% | Фенилаланин | 3.5% |
| Цистеин | 2,8% | Гистидин | 2,1 | Метионин | 1,7 | Триптофан | 1,1 |
Аминокислоты и белки — Биохимия
Если вы считаете, что контент, доступный через Веб-сайт (как определено в наших Условиях обслуживания), нарушает или другие ваши авторские права, сообщите нам, отправив письменное уведомление («Уведомление о нарушении»), содержащее в информацию, описанную ниже, назначенному ниже агенту.Если репетиторы университета предпримут действия в ответ на ан Уведомление о нарушении, оно предпримет добросовестную попытку связаться со стороной, которая предоставила такой контент средствами самого последнего адреса электронной почты, если таковой имеется, предоставленного такой стороной Varsity Tutors.
Ваше Уведомление о нарушении прав может быть отправлено стороне, предоставившей доступ к контенту, или третьим лицам, таким как в качестве ChillingEffects.org.
Обратите внимание, что вы будете нести ответственность за ущерб (включая расходы и гонорары адвокатам), если вы существенно искажать информацию о том, что продукт или действие нарушает ваши авторские права.Таким образом, если вы не уверены, что контент находится на Веб-сайте или по ссылке с него нарушает ваши авторские права, вам следует сначала обратиться к юристу.
Чтобы отправить уведомление, выполните следующие действия:
Вы должны включить следующее:
Физическая или электронная подпись правообладателя или лица, уполномоченного действовать от их имени; Идентификация авторских прав, которые, как утверждается, были нарушены; Описание характера и точного местонахождения контента, который, по вашему мнению, нарушает ваши авторские права, в \ достаточно подробностей, чтобы позволить репетиторам университетских школ найти и точно идентифицировать этот контент; например нам требуется а ссылка на конкретный вопрос (а не только на название вопроса), который содержит содержание и описание к какой конкретной части вопроса — изображению, ссылке, тексту и т. д. — относится ваша жалоба; Ваше имя, адрес, номер телефона и адрес электронной почты; а также Ваше заявление: (а) вы добросовестно полагаете, что использование контента, который, по вашему мнению, нарушает ваши авторские права не разрешены законом, владельцем авторских прав или его агентом; (б) что все информация, содержащаяся в вашем Уведомлении о нарушении, является точной, и (c) под страхом наказания за лжесвидетельство, что вы либо владелец авторских прав, либо лицо, уполномоченное действовать от их имени.
Отправьте жалобу нашему уполномоченному агенту по адресу:
Чарльз Кон
Varsity Tutors LLC
101 S. Hanley Rd, Suite 300
St. Louis, MO 63105
Или заполните форму ниже:
.